구름톤에서는 코딩테스트에 대해서 심도있게 다루고 있는 것 같다.
나도 수업에 잘 적응하고 싶기에 대비해 코테를 위한 파이썬 기초 문법을 복습했다.
전부 다 복습하지는 않았고, 내가 까먹었던 것들이나 다시 한 번 정리하면 좋을 것 같다는 생각이 든 것만 골라 정리했다.
f-string (f"...") 를 활용한 문자열 포맷팅
f-string은 Python 3.6 이상에서 도입된 문자열 포맷팅 방식으로, 간결하고 성능이 뛰어난 문자열 삽입 기능을 제공한다.
1. 기본 사용법
문자열 앞에 f 또는 F를 붙이면 중괄호 {} 안에 변수를 직접 삽입할 수 있다.
name = "재환"
age = 25
print(f"{name}은 {age}살입니다.")
# 출력: 재환은 25살입니다.2. 연산 및 표현식 삽입
f-string은 {} 안에서 연산과 함수 호출도 가능하다.
a, b = 5, 3
print(f"{a} + {b} = {a + b}")
# 출력: 5 + 3 = 8
def square(x):
return x * x
print(f"3의 제곱은 {square(3)}입니다.")
# 출력: 3의 제곱은 9입니다.3. 포맷 지정 (숫자, 정렬, 소수점)
(1) 소수점 자릿수 지정
pi = 3.1415926535
print(f"π 값: {pi:.2f}")
# 출력: π 값: 3.14(2) 정렬 및 공백 처리
name = "Python"
print(f"[{name:<10}]") # 왼쪽 정렬
print(f"[{name:^10}]") # 가운데 정렬
print(f"[{name:>10}]") # 오른쪽 정렬
# 출력:
# [Python ]
# [ Python ]
# [ Python](3) 천 단위 구분자
num = 1000000
print(f"{num:,}")
# 출력: 1,000,000(4) 진법 변환
num = 255
print(f"16진수: {num:x}, 8진수: {num:o}, 2진수: {num:b}")
# 출력: 16진수: ff, 8진수: 377, 2진수: 111111114. 딕셔너리, 리스트 값 삽입
person = {"name": "재환", "age": 25}
print(f"{person['name']}의 나이는 {person['age']}살입니다.")
# 출력: 재환의 나이는 25살입니다.
lst = [10, 20, 30]
print(f"리스트 값: {lst[0]}, {lst[1]}, {lst[2]}")
# 출력: 리스트 값: 10, 20, 305. 이스케이프 문자 사용 ({{ }})
f-string에서 {}를 출력하려면 중괄호를 두 번 사용해야 한다.
print(f"중괄호를 출력하려면 {{ 이렇게 }} 해야 합니다.")
# 출력: 중괄호를 출력하려면 { 이렇게 } 해야 합니다.6. 진법 변환
num = 255
print(f"10진수: {num}") # 기본 10진수
print(f"2진수: {num:b}") # 2진수 변환
print(f"8진수: {num:o}") # 8진수 변환
print(f"16진수: {num:x}") # 16진수 변환 (소문자)
print(f"16진수: {num:X}") # 16진수 변환 (대문자)문자열 함수
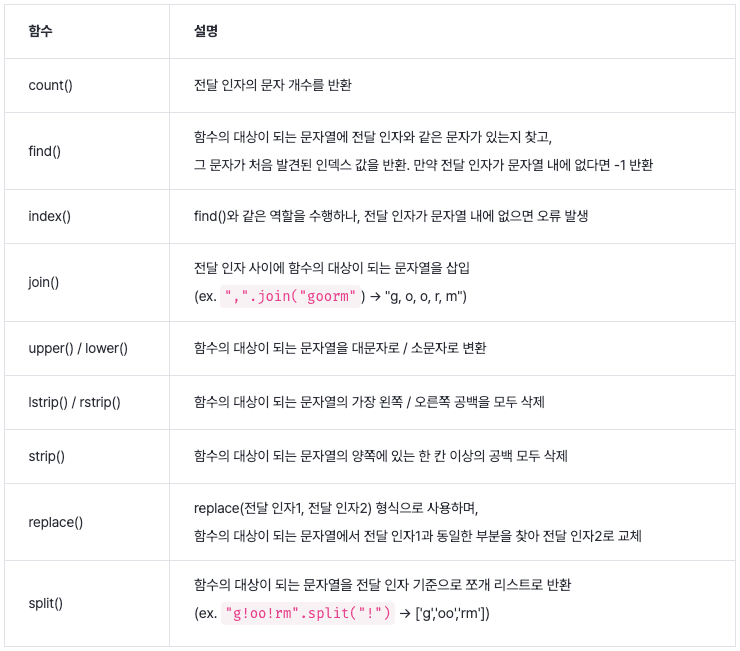
리스트(List) 연산
기본 연산
리스트 연산은 기본적으로 문자열 연산과 동일한 기능을 수행한다.
리스트 수정
문자열은 불변 타입이므로 인덱싱으로 값을 수정할 수 없으나 리스트에서는 가능하다.
리스트 수정 시 인덱싱 및 슬라이싱을 사용할 수 있다.
인덱싱의 경우 지정한 리스트 요소에 값을 대입하는 기능이고,
슬라이싱의 경우 시작 지점을 기준으로 값을 추가하는 기능이다.
numbers = [2, 4, 6, 8]
# 인덱싱을 수행하지 않고 슬라이싱을 수행했을 경우
# 결과 : [2, 4, 'a', 'b', 'c', 6, 8]
# 해당 문자열이 문자로 슬라이싱된 이후 추가(append)
numbers[2:3] = ['a','b','c']
print(numbers)
# 인덱싱을 수행한 경우
# 결과 : [2, 4, ['a', 'b', 'c'], 6, 8]
# 리스트 전체를 형태 유지하며 대입
numbers[2] = ['a', 'b', 'c']
print(numbers)리스트 삭제
리스트 삭제는 인덱싱, 슬라이싱, del 키워드를 사용하면 된다.
인덱싱과 슬라이싱은 엄밀히 말하면 객체를 삭제하는 것이 아니라 값을 공백으로 대체하는 것이다.
del 키워드는 객체 자체를 삭제해 메모리 공간을 확보한다.
리스트 함수
- append(x) : 리스트 맨 마지막에 요소를 추가한다.
- insert(x, y) : x 번째 위치에 y 값을 추가한다.
- extend(x) : 기존 리스트에 x를 합친다. 인수는 리스트만 사용할 수 있다.
- remove(x) : 리스트에서 가장 처음 나오는 x 값을 삭제한다.
- pop() : 리스트의 마지막 요소를 반환한 뒤 값을 삭제한다.
- sort() : 리스트의 요소를 정렬한다.
- reverse() : 리스트의 요소를 역정렬한다.
- index(x) : 리스트에서 가장 처음 나오는 인덱스 값을 반환한다.
- count(x) : 리스트에 있는 x의 값의 개수를 반환한다.
- len(x) : 인수가 리스트인 경우, 요소의 개수를 반환한다.
딕셔너리(Dictionary)
딕셔너리는 리스트와 달리 순서를 보장하지 않으므로 초기화 후 아무렇게나 값을 추가할 수 있다.
- {”key”:”value”} 형태로 구성된다.
- key는 value를 찾기 위한 유일한 값이므로 중복은 불가하다.
- key에 리스트를 사용할 수 없다.
- value에는 어떤 값이든 사용할 수 있다.
딕셔너리의 값을 삭제하고 싶을 때는 del 키워드를 이용해 삭제할 수 있다.
dic1 = {"apple":"사과", "bird":"새", "bug":"벌레"}
print(dic1)
del dic1["bug"]
print(dic1)딕셔너리 함수
참고로 딕셔너리 함수를 이용해 반환된 객체 형식을 리스트로 전환할 수 있다.
- x.keys() : 딕셔너리 x의 key만 모아 객체 형식 dict_keys([key1, key2, …])으로 반환한다.
- x.values() : 딕셔너리 x의 value만 모아 객체 형식 dict_valuess([value1, value2, …])으로 반환한다.
- x.items() : 딕셔너리 x의 key와 value를 튜플로 묶어 dict_items([(key1, value1), (key2, value2), …]) 형식으로 반환한다.
- x.clear() : 딕셔너리의 모든 값을 삭제한다.
- x.get(key) : x[key]와 동일한 기능으로 해당 key의 value를 반환한다.
- key in x : key 값이 x 딕셔너리 안에 존재하는지 판별하는 키워드이다.
튜플(Tuple)과 집합(Set)
비교
튜플(Tuple)
- 순서가 중요한 경우
- 중복을 허용해야 하는 경우
- 불변성을 유지해야 하는 경우 (데이터 보호) → 변경이 잦지 않은 데이터
- 리스트보다 성능이 중요할 때 (튜플이 더 빠름) → 리스트와 유사해 인덱싱 접근도 가능함
집합(Set)
- 순서가 필요 없는 경우
- 중복을 자동으로 제거해야 하는 경우
- 집합 연산(합집합, 교집합 등)을 사용해야 하는 경우
튜플 사용법
튜플은 소괄호를 사용한다.
이때 요소가 한 개인 경우에는 , 를 사용해야 한다.
t1 = ('a', 'b', 'c', 1, 2, 3)
t2 = ("hello",) #하나의 값이면 뒤에 콤마 입력주의해야 할 점으로는 튜플은 선언 시 괄호 생략이 가능하다는 것이다.
하지만 가급적 명시적으로 사용하는 것이 좋을 것 같다.
t3 = "goorm", 'b', "hello", 1, 2, 3 #괄호 생략 가능튜플 안에는 어떠한 자료형도 다 담을 수 있다.
중요한 점은 담긴 자료형이 mutable 하면 수정이 가능하다.
s1 = list(set([1,2,3]))
t4 = ([1, 2, 3], {"사과":"apple", "포도":"grape"}, ('a', 'b', 'c'), s1)
#결과 : ([1, 2, 'edit'], {'사과': 'edit', '포도': 'grape'}, ('a', 'b', 'c'), [1, 2, 'edit'])튜플은 리소스와 유사한 자료형이라고 언급한 바 있다.
더하기, 곱셈 연산이 가능하고, index(x), count(x) 함수 등을 사용할 수 있다.
리스트 함수에서 값을 변경하지 않는 함수들은 대부분 사용할 수 있는 것이다.
t1 = ('a', 'b', 'c', 1, 2, 3)
t2 = ("hello",)
t3 = "goorm", 'b', "hello", 1, 2, 3
print(t1 + t2 + t3) #튜플 결합
print(t2 * t3[4]) #곱셈으로 반복 출력집합 사용법
집합은 중괄호를 사용한다.
s1 = {3, 2, 5, 1, 8, 4, 3} #집합으로 바로 선언 및 초기화
print(s1, type(s1))다른 자료형을 집합(Set)형으로 변경할 수 있다.
변경되는 과정에서 다음과 같은 변화가 일어난다.
- 요소의 순서가 없어진다.
- 중복되는 값은 한 개만 저장된다.
- 딕셔너리가 변경될 경우 key만 저장된다.
집합형은 리스트 혹은 튜플에 속한 요소의 중복을 제거하기 위한 필터로 사용되기도 한다.
다만 인덱싱 혹은 슬라이싱을 할 수가 없어 중복을 제거한 후에는 다시 리스트나 튜플로 변경해야 한다.
변경하기 위해서는 set() 함수를 사용하면 된다.
str = "Hello goorm!!!"
s0 = set(str) 또한 아래와 같이 합집합, 교집합, 차집합 연산을 수행할 수 있다.
s1 = set([2,4,6,8,10])
s2 = set([1,2,3,4,5,6,7,8])
interset = s1 & s2 #교집합
print(interset)
print(s1.intersection(s2), s2.intersection(s1)) #함수 사용
print(s1) #s1의 값이 바뀌는 것이 아님
uniset = s1 | s2 #합집합
print(uniset)
print(s1.union(s2))
print(s1) #s1의 값이 바뀌는 것이 아님
difset1 = s1 - s2 #어떤 집합에서 어떤 집합을 빼느냐에 따라 다른 결괏값
difset2 = s2 - s1
print(difset1)
print(difset2)집합 함수
집합 함수 사용 시 주의해야 할 점은 튜플은 한 개의 원소로 사용할 수 있으나 리스트와 집합 자체는 집합의 원소로서 사용할 수 없다.
- set.add(a) : 집합 set에 a 값을 추가한다.
- set.update([a,b,c]) : 집합 set에 여러 개의 값을 추가한다.
- set.remove(a) : 집합 set에 a 값을 삭제한다.
s1.update(['a', 'b', 'c']) 의 경우 인자만 리스트인 것이고 이후 ‘a’, ‘b’, ‘c’ 가 각각 구분돼 저장된다.
s1 = {1, 2, 3, 4}
s1.add("hello") # "hello" 라는 문자열이 저장된다. update를 사용하면 각 문자가 분리돼 저장된다.
print(s1)
s1.add(10)
print(s1)
s1.add((1,2,3)) #add() 사용 시 튜플/문자열은 값 하나로 인식
print(s1)
s1.update(['a', 'b', 'c']) #set()과 같이 여러 값을 한 요소로 저장
s1.update((11,12))
print(s1)
s1.update("zyx") #s1.add("hello")와의 차이 -> 'z', 'y', 'x'가 각자 저장된다.
print(s1)
s1.remove("hello") #하나의 값만 제거 가능
print(s1)파이썬 함수의 매개변수
함수 호출 시 매개변수 지정 가능
파이썬에서는 함수 호출 시 매개변수를 지정하여 전달할 수 있다.
def subNums(a, b) :
return a - b
num = 13
print(subNums(b = 20, a = num)) # 결과 값이 -7로 나온다.가변 인자 함수
파이썬에서는 동일한 기능을 수행하지만 매개변수만 다른 함수를 가변 인자 함수로 지정할 수 있다.
def sumSevenNums(a, b, c, d, e, f, g) :
return a + b + c + d + e + f + g
def sumThreeNums(a, b, c) :
return a + b + c
print(sumSevenNums(1, 3, 4, 2, 3, 4, 5))
print(sumThreeNums(1, 5, 10))위 코드의 경우, 동일한 비즈니스 로직을 가지고 있지만 매개변수의 개수가 다르다.
파이썬에서는 def 함수 이름(*매개변수): 형식으로 선언해 이를 해결할 수 있다.
가변 인자는 ‘튜플’ 형식으로 저장된다.
가변 인자가 ‘튜플’ 형식으로 저장되는 이유는 인자를 얼마나 다양한 인자가 전달될지 모르기 때문이다.
def subNums(*t) :
print(t, type(t)) # 전달된 가변 인자는 '튜플' 형식으로 저장된다.
total = 0
for i in t :
total = total + i
return total
print(subNums(1, 3, 4, 2, 3, 4, 5))
print(subNums(1, 5, 10))가변 인자 함수의 매개변수는 필요에 따라 가변 인자와 일반 매개변수를 함께 사용할 수 있다.
def calNums(ch, *t) :
if ch == "sum" : #모든 값을 더합니다.
total = 0
for i in t :
total = total + i
elif ch == "mul" : #모든 값을 곱합니다.
total = 1
for i in t :
total = total * i
else :
print("실행할 수 없습니다.")
return total
choice = input("덧셈은 sum, 곱셈은 mul를 입력하세요:")
print(calNums(choice, 1, 2, 3, 2, 5, 3, 2)) 키워드 매개변수
파이썬에서는 인자로 딕셔너리를 받기 위해서 키워드 매개변수라는 용법을 사용한다.
매개변수 앞에 ** 를 입력하면 함수 호출 시 전달인자를 (key1=value1, key2=value2, …) 형식으로 입력해 딕셔너리 형태를 전달할 수 있다.
이때 주의해야 할 점은 딕셔너리를 인자로 전달할 때는 key 값을 따옴표로 감싸면 안 된다.
def func(**kwargs) :
print(kwargs)
num = 10
func(apple="사과", a = num, num = 4) # 원래 딕셔너리는 { "apple" : "사과" } 형식이다.반환 값
다른 언어에서는 어떤 자료형의 값을 몇 개 반환할 것인지 함수를 선언할 때 명시해야 하고, 선언한 대로 반환해야 한다.
하지만 파이썬의 경우, 반환 값 자체를 함수에 명시하지 않고 return 뒤에 반환할 값을 입력만 하면 된다.
주의해야할 점은 반환 값에 맞게 최소한의 같은 개수의 변수에 할당해야 한다.
def calculator(a, b) :
sum = a + b
sub = a - b
mul = a * b
div = a / b
return sum, sub, mul, div
res1, res2, res3, res4 = calculator(10, 2)
print(res1, res2, res3, res4)이때, 예외적으로 한 개의 변수만 사용하는 것은 가능하다.
반환 값이 여러 개인 경우 파이썬 자체에서 내부적으로 튜플로 묶어 반환하기 때문이다.
def calculator(a, b) :
sum = a + b
sub = a - b
mul = a * b
div = a / b
return sum, sub, mul, div
reslist = calculator(10, 2)
print(reslist, type(reslist))
# 결과 : (12, 8, 20, 5.0) <class 'tuple'>클래스
객체와 클래스 변수
클래스 변수는 클래스 안에서 선언된 변수를 의미한다.
클래스 변수는 같은 클래스로 만들어진 인스턴스끼리 공유하고 접근이 가능한 변수이다.
클래스 변수의 값은 해당 클래스를 활용해 생성되는 모든 객체에 영향을 주므로 신중하게 설정해야 한다.
인스턴스 변수와 메소드
메소드를 활용해 객체 정보를 Set하는 함수를 생성할 수 있다.
이때 매개변수 self 를 사용해야 한다.
self 는 실제 메소드를 사용할 때 사용자에게 전달 인자를 입력받지 않고, 객체를 전달받아 각 매개 변수에 값을 할당해 주는 역할을 수행한다.
class Triangle :
def setData(self, b, h) : #메소드
self.b = b
self.h = h
tri1 = Triangle() #객체 생성
tri1.setData(4, 5) #객체 메소드 실행
print(tri1.b, tri1.h)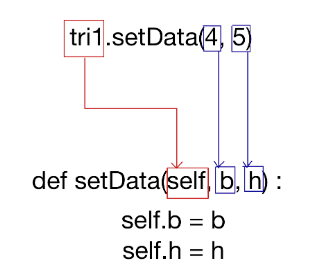
이때 self.b 와 self.h 형태로 사용되는 변수들을 인스턴스 변수라고 칭한다.
클래스 변수와 인스턴스 변수의 차이점
인스턴스 변수의 경우 전달받은 인스턴스에 대한 변수 값을 변경하기 위해 self 에 접근한다.
반면 클래스 변수의 경우 클래스명인 Triangle 에 접근해 값을 변경한다.
class Triangle :
cal_count = 0
def __init__(self, b, h = 5) : #생성자
self.b = b
self.h = h
def area(self) :
Triangle.cal_count += 1
return self.b * self.h / 2
tri1 = Triangle(4)
tri2 = Triangle(6, 10)
print(tri1.b, tri1.h, tri1.area(), tri1.cal_count)
print(tri2.b, tri2.h, tri2.area(), tri2.cal_count)
print(Triangle.cal_count)생성자
생성자는 객체 생성 시 인스턴스 변수의 값을 설정하기 위한 메소드이다.
__init__ 이름을 사용해 정의해야 한다.
이를 통해 객체 생성 후 인스턴스의 변수 값 할당을 위해 사용했던 setTriangle 함수를 더 이상 사용하지 않아도 된다.
객체 생성 시 전달하는 인자 값이 파이썬 내부 로직에 의해 생성자에 전달돼 인스턴스 변수에 값이 할당된다.
class Triangle :
def __init__(self, b, h) : #생성자
self.b = b
self.h = h
def area(self) :
return self.b * self.h / 2
tri1 = Triangle(4, 5) #호출하면서 바로 인자 전달
tri2 = Triangle(6, 10)
print(tri1.b, tri1.h, tri1.area())
print(tri2.b, tri2.h, tri2.area())정적 메소드, 인스턴스 메소드, 클래스 메소드
class Triangle :
cal_count = 0
def __init__(self, b, h = 5) :
self.b = b
self.h = h
def area(self) :
Triangle.cal_count += 1
return self.b * self.h / 2
@staticmethod
def isIsosceles(a, b) :
Triangle.cal_count += 1
return a == b
@classmethod
def printCount(cls) :
print(cls.cal_count)
tri1 = Triangle(4) #밑변 4 삼각형 객체 생성
print(tri1.b, tri1.h, tri1.area(), tri1.cal_count)
print(Triangle.isIsosceles(5,4))
tri1.printCount() #인스턴스로 접근
Triangle.printCount() #클래스로 직접 접근정적 메소드 (독립적인 기능)
self 매개변수나 cls 매개변수를 갖지 않는 메소드이다.
즉, 인스턴스나 클래스 상태와 관계없이 동작하는 메소드이다.
따라서 인스턴스를 생성하지 않고도 해당 메소드를 호출할 수 있다.
그렇기 때문에 객체와 무관한 보조 기능(일반적인 유틸리티 함수)을 구현할 때 사용한다.
주의해야 할 점으로는 @statcmethod 키워드를 사용해 정적 메소드임을 선언해야 한다.
class MathUtil:
@staticmethod
def add(a, b): # 정적 메서드
return a + b
# 인스턴스를 만들지 않고 클래스에서 직접 호출 가능
print(MathUtil.add(3, 5)) # 8인스턴스 메소드 (인스턴스 관련 기능)
self 키워드를 사용해 인스턴스의 필드에 접근하는 메소드를 말한다.
개별 객체에 종속되는 동작을 정의할 때 사용한다.
인스턴스를 통해서만 호출할 수 있다.
class Car:
def __init__(self, brand):
self.brand = brand # 인스턴스 변수
def show_brand(self): # 인스턴스 메서드
print(f"Car brand: {self.brand}")
car1 = Car("Tesla")
car1.show_brand() # Car brand: Tesla클래스 메소드 (클래스 레벨 관리)
cls 키워드를 사용해 클래스 변수에 접근하는 메소드를 말한다.
주로 클래스 상태를 변경하는 기능을 구현할 때 사용한다.
정적 메소드처럼 클래스 명으로 직접 호출이 가능하다.
class Car:
total_cars = 0 # 클래스 변수
def __init__(self, brand):
self.brand = brand
Car.total_cars += 1 # 인스턴스가 생성될 때마다 증가
@classmethod
def get_total_cars(cls): # 클래스 메서드
return f"Total cars: {cls.total_cars}"
car1 = Car("Tesla")
car2 = Car("BMW")
print(Car.get_total_cars()) # Total cars: 2요약

클래스 상속
고유 특징들을 공통 분모로 묶고 부모 클래스로 만든다.
부모 클래스를 상속받은 자식 클래스들은 부모 클래스의 메소드와 변수에 접근할 수 있다.
필요에 따라 부모 클래스의 메소드를 오버로딩 하거나 오버라이딩 할 수 있다.
파이썬에서의 오버로딩과 오버라이딩
오버로딩과 오버라이딩의 개념적 정의를 먼저 훑어보자.
두 용어는 모두 부모 클래스의 메소드를 자식 클래스에서 같은 이름으로 재정의한다는 공통점이 있다.
하지만 재정의하는 목적과 선언하는 위치 자체가 다르다.
오버로딩은 같은 클래스 내에서 같은 로직을 사용하지만, 다양한 입력 값을 유연하게 대응하도록 동작하게 하는 것이 목적이다.
하지만 파이썬은 런타임에 자료형이 결정되는 동적 타입 언어이므로, 자바/C++과 달리 매개변수의 타입을 고려해야하는 오버로딩 기능이 지원되지 않는다.
대신 우리는 가변 인자 함수를 활용하면 된다.
쉽게 말하면 아래와 같이 *args 를 통해 여러 개의 인자를 받을 수 있다는 것이다.
class Example:
def add(self, *args):
return sum(args)
obj = Example()
print(obj.add(1)) # 1
print(obj.add(1, 2)) # 3
print(obj.add(1, 2, 3)) # 6오버라이딩은 부모 클래스의 메소드를 상속된 자식 클래스가 재정의해 로직을 수정하는 것이 목적이다.
파이썬에서 공식적으로 지원된다.
super() 함수를 사용해 부모 클래스에 접근하여 메소드를 호출할 수 있다.
class Parent:
def greet(self):
print("Hello from Parent")
class Child(Parent):
def greet(self):
super().greet() # 부모의 greet() 호출
print("Hello from Child")
obj = Child()
obj.greet()여담으로 super() 함수는 다음과 같은 사례에 사용된다.
- 부모 클래스의 메서드를 호출할 때 사용
- 오버라이딩한 메서드에서 부모의 기능을 유지하면서 추가 기능을 구현 가능
- 생성자(__init__)에서도 활용 가능
- 다중 상속에서도 부모 클래스의 메서드를 명확하게 호출할 수 있음
그렇다고 반드시 부모 클래스의 기능을 활용하는 것이 객체지향의 필수 규칙은 아니다.
오버라이딩(Overriding)의 핵심은 부모의 기능을 변경(재정의)하거나 확장하는 것이다.
따라서, 부모의 기능이 필요 없으면 완전히 새로운 메서드로 덮어쓰는 것도 가능
클래스 메소드의 클래스 변수 접근 범위
클래스 메소드(@classmethod)는 cls 키워드를 통해 클래스 변수를 참조한다.
자식 클래스에서 부모의 클래스 메소드를 호출하면, 자식 클래스의 클래스 변수를 참조한다.
class Parent:
class_var = "Parent Variable"
@classmethod
def show_class_var(cls):
print(f"Class variable: {cls.class_var}")
class Child(Parent):
class_var = "Child Variable" # 부모 클래스의 class_var를 덮어씀
child_instance = Child()
child_instance.show_class_var() # 자식 클래스의 class_var 참조인스턴스의 메소드 접근 범위
- 자식 클래스의 인스턴스 → 부모 클래스의 접근 범위
- 부모 클래스의 인스턴스 → 자식 클래스의 접근 범위
다중상속
파이썬은 다른 언어와 달리 다중 상속을 지원한다.
다른 객체 지향 언어들은 두 부모 클래스에 있는 생성자 메소드의 충돌 여부 등을 고려해 설계 당시 이를 금지했다.
파이썬의 경우 MRO(Method Resolution Order, 메소드 탐색 순서, 왼→오)를 따라 이 문제를 회피하도록 설계했다.
class First :
name = "first"
def __init__(self) :
print("First class")
def printFirst(self) :
print("first")
class Second :
name = "second"
def __init__(self) :
print("First class")
@classmethod
def printName(cls) :
print(cls.name)
#상속해야 할 부모클래스가 두 개인 경우 충돌 가능
#파이썬은 MRO에 따라 다중 상속을 진행
class Third(First, Second) :
pass
third = Third()
third.printName() # 다중 상속으로 Second의 메소드를 사용할 수 있다.
third.printFirst() # MRO에 따라 First의 생성자 함수로 인스턴스가 초기화 됐다.
# 결과
# First class
# first
# frist예외처리
try ~ finally 문을 사용하여 예외처리를 수행할 수 있다.
- try 항목에는 실행될 코드가 위치한다.
- except 에러이름 as 에러메세지변수 항목에는 에러 발생 시 실행할 코드가 위치한다.
- else 항목에는 에러가 발생하지 않았을 때 실행될 코드가 위치한다.
- finally 항목에는 except 항목이던 else 항목이던 try 가 끝나면 실행될 코드가 위치한다.
try:
10 / 2
except ZeroDivisionError as e:
print(e)
else:
print("Success!")
finally:
print("ZeroDivisionError Check")pass 키워드를 사용해 오류를 무시할 수 있다.
try:
10 / 0
except ZeroDivisionError:
passraise 키워드를 사용해 에러를 발생시킬 수 있다.
이 키워드를 잘 활용하면 개발자가 직접 에러를 애플리케이션에 맞게 커스터마이징해 핸들링할 수 있다.
try:
raise NameError
except NameError:
print("NameError occurred")'Tech > [Lang] Python' 카테고리의 다른 글
| [Python] Excel 템플릿을 기반으로 PDF 파일 견적서 자동 발행 (0) | 2021.07.14 |
|---|
