대용량 트래픽을 처리하기 위해서는 서비스 안정성, 확장성, 비용 최적화, 고가용성을 목표로 시스템을 설계해야 한다.
이에, 현대 개발환경은 요구사항에 맞추어 다양한 종류의 컴퓨팅 아키텍처를 활용하고 있다.
그 중 주로 사용하는 아키텍처들의 이론에 대해서 정리해 보았다.
작업 부하 분산 아키텍처 (Workload Distribution Architecture)
개념 (Definition)
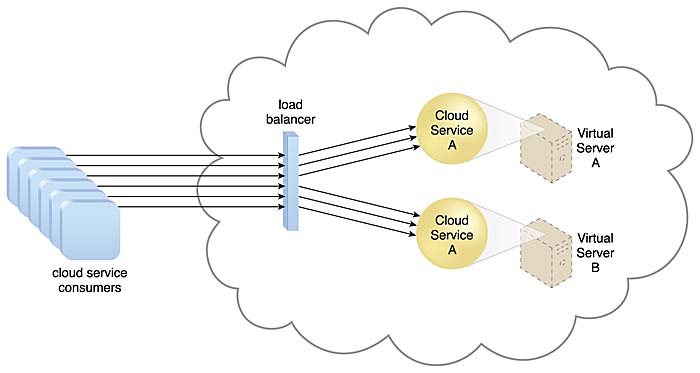
작업 부하 분산 아키텍처란, 동일한 IT 자원을 여러 개 수평적으로 확장(Horizontal Scaling, Scale Out)하고, 로드 밸런서(Load Balancer)를 통해 사용자 요청 및 작업을 고르게 분산하는 구조를 말한다.
이 아키텍처는 과도한 자원 사용(Over-utilization) 및 자원 미사용(Under-utilization) 문제를 최소화하여 IT 자원의 효율적인 운영을 지원한다.
분산 수준은 로드 밸런서의 알고리즘 및 런타임 논리에 따라 달라진다.
동작 방식 (How it Works)
- 로드 밸런서가 클라우드 서비스 소비자의 요청을 가로채어, 여러 가상 서버(IT 자원)에 균등하게 분산한다.
- 예: Cloud Service A가 Virtual Server A, B에 복제되어 동작하며, 로드 밸런서가 요청을 두 서버에 고르게 전달 (그림 참조).
적용 대상 (Applicable IT Resources)
작업 부하 분산 아키텍처는 다양한 IT 자원에 적용될 수 있으며, 다음과 같은 자원을 대상으로 한다.
- 가상 서버 (Virtual Servers)
- 클라우드 스토리지 장치 (Cloud Storage Devices)
- 클라우드 서비스 (Cloud Services)
이 외에도 특수한 형태로 다음 아키텍처에 응용된다.
- 서비스 로드 밸런싱 아키텍처 (Service Load Balancing Architecture)
- 가상 서버 로드 밸런싱 아키텍처 (Load Balanced Virtual Server Architecture)
- 가상 스위치 로드 밸런싱 아키텍처 (Load Balanced Virtual Switches Architecture)
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
대규모 웹 서비스 운영
|
사용자 요청을 여러 서버로 분산하여 성능 저하 방지.
|
|
클라우드 기반 데이터 분석 플랫폼
|
데이터 처리 부하를 여러 서버로 분산하여 고성능 처리.
|
|
온라인 게임 서버
|
동시 접속자 분산 처리로 게임 서비스의 원활한 운영 보장.
|
|
API 서비스 플랫폼
|
다수의 API 요청을 서버 간 고르게 분산.
|
|
대용량 파일 처리 서비스
|
스토리지 장치 간 부하 분산을 통해 데이터 접근 속도 향상.
|
기대 효과 (Benefits)
- 고가용성(High Availability): 한 자원이 실패해도 다른 자원이 작업을 이어받음.
- 성능 향상 (Performance Boost): 자원을 동적으로 추가/제거하여 부하 대응.
- 비용 최적화 (Cost Efficiency): 자원을 필요한 만큼만 할당, 불필요한 자원 사용 방지.
- 확장성 (Scalability): 수평적 확장으로 트래픽 급증 대응 가능.
자원 풀링 아키텍처 (Resource Pooling Architecture)
개념 (Definition)
자원 풀링 아키텍처란, 동일한 유형의 IT 자원(서버, 스토리지, 네트워크, CPU, 메모리 등)을 하나의 자원 풀(Pool)로 묶어 중앙에서 일괄 관리하고, 필요 시 클라우드 소비자나 서비스에 자동으로 할당하는 구조이다.
이 아키텍처는 자원들을 논리적으로 그룹화하여 관리함으로써 빠른 자원 할당, 확장성, 유연성, 비용 최적화를 제공하며, 자원들은 상태가 동기화(Synchronized) 되어 관리된다.
동작 방식 (How it Works)
- 동일한 유형의 IT 자원을 하나의 풀로 그룹화하고, 중앙 자원 관리 시스템이 자원의 상태를 지속적으로 동기화 및 관리한다.
- 사용자가 자원을 요청하면 자원 관리 시스템이 미리 준비된 자원 풀에서 즉시 할당하여 빠른 서비스 제공이 가능하다.
- 자원의 수요에 따라 자동으로 자원을 확장하거나 회수할 수 있으며, 사용 후에는 풀로 반환하여 재사용 가능하다.
- 자원 풀은 필요한 목적에 따라 서브 풀(Sub Pool, 하위 풀)로 세분화해 더욱 세밀한 관리가 가능하다.
- 예를 들어, 가상 서버 풀, 스토리지 풀, 네트워크 풀, CPU 풀, 메모리 풀 등이 존재할 수 있으며, 복합 풀 형태로도 운영 가능하다.
형제 자원 풀 (Sibling Resource Pool)
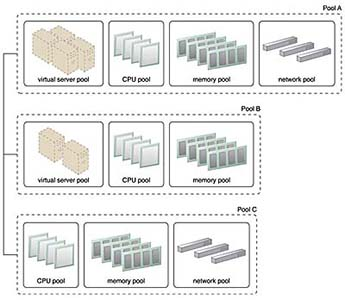
형제 자원 풀은 동일한 상위 풀에서 독립적으로 분리된 자원 풀로서 수평적 관계에 있는 자원 그룹이다.
형제 풀은 서로 간에 영향을 주지 않으며, 각기 독립적으로 운영된다.
예를 들어, A 기업과 B 기업에 각각 독립적으로 할당된 서버 풀과 같은 형태로, 멀티 테넌트 환경에서 고객별로 자원을 분리하여 보안성과 독립성을 확보할 때 적합하다.
형제 풀은 일반적으로 물리적으로 가까운(동일 데이터센터) 자원으로 구성되며, 각 풀 간 격리를 통해 한 풀의 문제가 다른 풀에 영향을 주지 않도록 설계된다.
중첩 풀 (Nested Resource Pool)
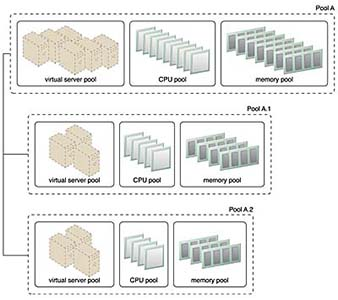
중첩 풀은 상위 풀에서 계층적으로 하위 풀(서브 풀, Sub Pool)로 세분화된 구조로, 부서별, 팀별로 자원을 세밀하게 분할하여 사용할 때 적합하다.
상위 풀에서 자원의 일정 부분을 하위 풀로 할당하며, 상위 풀과 하위 풀은 종속 관계에 있다.
예를 들어, 회사의 개발 부서라는 상위 풀 내에서 프론트엔드 팀과 백엔드 팀으로 나누는 것이 중첩 풀의 사례이다.
중첩 풀을 통해 같은 유형의 자원을 필요에 따라 동일한 설정 및 조건으로 일관되게 분할하여 사용 가능하다.
적합한 사용 사례 (Use Cases)
- 멀티 테넌트 SaaS 서비스에서 고객마다 독립된 자원을 제공해야 할 때.
- 빠른 애플리케이션 배포 및 확장이 필요한 환경.
- 기업 내 부서별 자원 분리 및 할당이 필요한 경우.
- 비용 최적화를 위해 사용하지 않는 자원을 효율적으로 관리하고자 할 때.
- 클라우드 플랫폼에서 자원의 동적 할당 및 회수가 필요할 때.
기대 효과 (Benefits)
- 자원 사용 최적화: 미사용 자원을 하나로 묶어 관리하여 낭비 방지.
- 빠른 서비스 프로비저닝: 요청 시 즉각 자원 할당 가능.
- 유연한 확장 및 축소: 필요에 따라 자원 확장 또는 회수.
- 비용 절감: 자원의 통합 관리로 불필요한 중복 비용 절감.
- 보안 및 격리: 독립된 풀 구성으로 고객 또는 부서 간 자원 격리.
- 일관된 자원 구성 제공: 중첩 풀을 통한 일관된 자원 정책 적용.
동적 확장 아키텍처 (Dynamic Scalability Architecture)
개념 (Definition)
동적 확장 아키텍처(Dynamic Scalability Architecture)는 미리 정의된 확장 조건(Scaling Condition)에 따라 자동으로 IT 자원을 동적으로 할당하거나 회수하는 구조이다.
사용량 변화에 따라 자원을 자동으로 증설하거나 축소하여 최적의 자원 사용, 성능 유지, 비용 절감을 동시에 달성하는 클라우드 아키텍처 모델이다.
이 아키텍처의 핵심은 자동화된 확장 리스너(Auto Scaling Listener)로, 실시간 워크로드를 모니터링하고 자원 할당을 자동으로 결정 및 실행한다.
동작 방식 (How it Works)
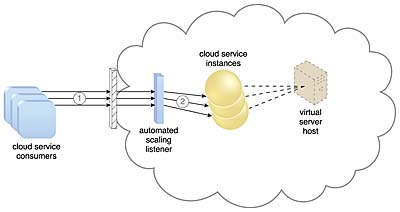
(1) 클라우드 서비스 소비자가 클라우드 서비스에 요청을 보내고 있다.
(2) 자동화된 스케일링 리스너는 클라우드 서비스를 모니터링하여 사전 정의된 용량 임계값을 초과하는지 확인한다.
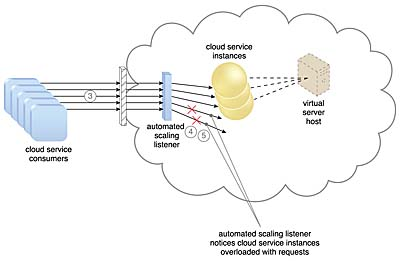
(3) 클라우드 서비스 소비자로부터 오는 요청 수가 증가한다.
(4) 작업 부하가 성능 임계값을 초과하면, 자동화된 스케일링 리스너는 사전 정의된 스케일링 정책에 따라 다음 조치 과정을 결정한다.
(5) 클라우드 서비스 구현이 추가 스케일링에 적합하다고 간주되면 자동화된 스케일링 리스너가 스케일링 프로세스를 시작한다.
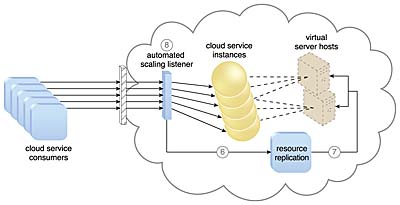
(6) 자동 스케일링 리스너는 리소스 복제 메커니즘에 신호를 보낸다.
(7) 클라우드 서비스의 인스턴스를 더 많이 만든다.
(8) 이제 적절하게 부하를 처리할 수 있게 됐다. 이후 위 과정을 반복하며 자동으로 Scale In & Scale Out를 수행한다.
동적 확장의 유형 (Types of Dynamic Scaling)
1) 동적 수평 확장 (Dynamic Horizontal Scaling)
- 가상 서버 인스턴스를 복제/제거하여 워크로드에 따라 자원 수를 조절.
- 예: 사용자가 몰리면 웹 서버를 3개 → 10개로 자동 확장, 이후 감소 시 다시 축소.
- Scale-Out, Scale-In 방식.
2) 동적 수직 확장 (Dynamic Vertical Scaling)
- 기존 IT 자원의 성능(메모리, CPU 코어 등)을 확장/축소.
- 예: CPU 코어 추가, 메모리 증가.
- Scale-Up, Scale-Down 방식.
3) 동적 재배치 (Dynamic Relocation)
- 더 높은 성능의 하드웨어로 자원을 이동(재배치).
- 예: I/O가 많은 데이터베이스를 고성능 스토리지로 이동.
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
트래픽 급증이 예상되는 웹 서비스
|
사용자 수 증가에 따라 자동 확장으로 서비스 중단 방지.
|
|
계절적 이벤트가 있는 서비스 (예: 쇼핑몰, 게임 서버)
|
이벤트 기간 동안 자동 확장/종료로 비용 최적화.
|
|
데이터 분석/배치 작업이 많은 환경
|
데이터 양에 따라 자원 자동 확장 및 작업 완료 후 회수.
|
|
API 요청량이 급증하는 플랫폼
|
요청량에 따라 API 서버 자동 증설 및 축소.
|
기대 효과 (Benefits)
- 고가용성 (High Availability): 급격한 트래픽 증가에도 자동 확장으로 서비스 지속 가능.
- 성능 유지 (Performance Consistency): 사용자 증가에 따른 성능 저하 방지.
- 비용 절감 (Cost Efficiency): 필요 시에만 자원 사용, 미사용 시 회수로 비용 최적화.
- 운영 자동화 (Automation): 관리자의 수동 개입 없이 자원 자동 할당.
- 확장성 (Scalability): 서비스 수요에 맞는 자동 대응.
탄력적 자원 용량 아키텍처 (Elastic Resource Capacity Architecture)
개념 (Definition)
탄력적 자원 용량 아키텍처(Elastic Resource Capacity Architecture)란 가상 서버의 CPU, 메모리(RAM) 등의 IT 자원을 사용량에 맞게 자동으로 할당(Provisioning)하거나 회수(Reclaiming)하는 아키텍처이다.
호스팅된 IT 자원의 처리량 변화에 따라 즉각적으로 자원을 늘리거나 줄여 서비스의 안정성과 성능을 유지하면서 비용을 최적화할 수 있도록 지원한다.
이 아키텍처는 자동 확장(Auto-Scaling) 기술을 활용하지만, 주로 가상 서버의 수직 확장(Vertical Scaling)을 중심으로 동작한다.
탄력적 자원 용량 아키텍처는 클라우드 서비스의 부하에 따라 즉각적이고 자동으로 자원을 할당하고 회수할 수 있는 구조로, 성능 보장, 비용 최적화, 무중단 확장을 동시에 충족하는 필수적인 아키텍처이다.
특히 CPU, 메모리와 같은 컴퓨팅 자원의 수직 확장에 매우 적합하며, 클라우드 기반 서비스, AI/빅데이터, 웹 서비스, 비즈니스 애플리케이션에서 널리 사용될 수 있다.
동작 방식 (How it Works)
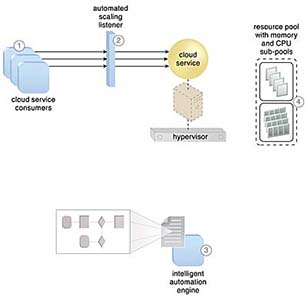
(1) 클라우드 서비스 소비자는 클라우드 서비스에 적극적으로 요청을 보내고 있다.
(2) 이는 자동화된 스케일링 리스너에 의해 모니터링됩니다.
지능형 자동화 엔진 스크립트는 할당 요청(4)을 사용하여 리소스 풀에 알릴 수 있는 워크플로 로직(3)과 함께 배포된다.
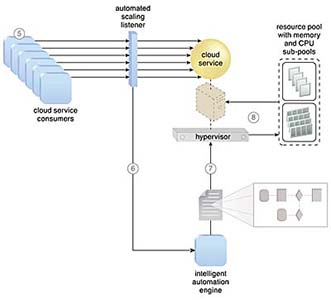
클라우드 서비스 소비자 요청이 증가(5)하여,
자동화된 스케일링 리스너가 지능형 자동화 엔진에 스크립트를 실행하도록 신호를 보낸다. (6)
스크립트는 하이퍼바이저에 리소스 풀에서 더 많은 IT 리소스를 할당하도록 신호를 보내는 워크플로 로직을 실행한다. (7)
하이퍼바이저는 가상 서버에 추가 CPU와 RAM을 할당하여 증가된 작업 부하를 처리할 수 있도록 한다. (8)
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
예상치 못한 트래픽 급증
|
서버의 CPU, 메모리를 즉시 확장하여 서비스 안정성 유지.
|
|
데이터 분석 작업으로 일시적 고성능 필요
|
데이터 처리 시 필요한 자원만 일시적으로 확장.
|
|
비용 최적화를 위한 탄력적 자원 운영
|
사용량 감소 시 자원 회수로 비용 절감.
|
|
리소스 제한된 환경에서 동적 확장 필요
|
정해진 가상 서버 내에서 수직적 자원 확장으로 대응.
|
기대 효과 (Benefits)
- 성능 향상 (Performance Improvement): 요청 증가 시 즉시 자원을 확장하여 서비스 성능 유지.
- 비용 절감 (Cost Optimization): 필요할 때만 자원을 사용하고, 사용 후 즉시 회수.
- 유연성 (Flexibility): 가상 서버 단위로 필요한 자원만 빠르게 할당/회수 가능.
- 고가용성 (High Availability): 서비스 중단 없이 실시간 확장 대응.
- 운영 자동화 (Automation): 관리자의 수동 개입 없이 자동 대응.
서비스 로드 밸런싱 아키텍처 (Service Load Balancing Architecture)
개념 (Definition)
서비스 로드 밸런싱 아키텍처(Service Load Balancing Architecture)란 클라우드 서비스(Cloud Service)의 부하를 분산하고 확장성을 확보하기 위한 특화된 분산 아키텍처이다.
즉, 동일한 클라우드 서비스 인스턴스를 여러 개 중복(복제) 배치하고, 로드 밸런서를 통해 사용자 요청을 동적으로 분산하여 서비스 처리 성능과 가용성을 높이는 구조이다.
이는 작업 부하 분산 아키텍처(Workload Distribution Architecture)의 서비스 중심 버전으로 볼 수 있다.
특히 API 서비스, SaaS, MSA 환경, 대량 요청 처리 서비스에 최적화된 구조로, 부하 증가, 장애 대응, 비용 최적화라는 주요 요구사항을 동시에 만족시킬 수 있다.
동작 방식 (How it Works)
외부 독립 로드 밸런서 방식 (External Load Balancer)
- 로드 밸런서가 사용자 요청을 받아 여러 서비스 인스턴스로 분배.
- 클라우드 서비스와 독립적.
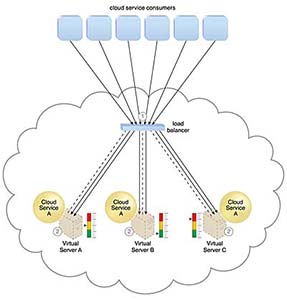
로드 밸런서는 클라우드 서비스 소비자가 보낸 메시지를 가로채서(1)
가상 서버로 전달하여 워크로드 처리를 수평적으로 확장한다. (2)
내장 로드 밸런서 방식 (Built-in Load Balancer)
- 클라우드 서비스 내부에 로드 밸런싱 로직 내장.
- 주 서버가 인접 서버와 통신하여 분산 처리.
- 마이크로서비스(MSA), P2P 서비스에 적합.
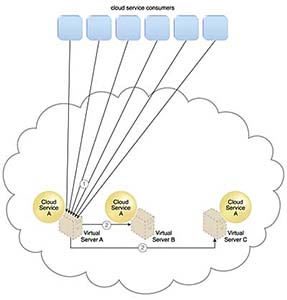
클라우드 서비스 소비자 요청은 가상 서버 A의 클라우드 서비스 A로 전송된다. (1)
클라우드 서비스 구현에는 가상 서버 B와 C의 이웃 클라우드 서비스 A 구현에 요청을 분산할 수 있는 내장 로드 밸런싱 로직이 포함된다. (2)
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
API 게이트웨이 트래픽 분산
|
수천~수만 건의 API 요청을 여러 서비스 인스턴스로 고르게 분산.
|
|
고객 수 급증 서비스 (예: 쇼핑몰, 예약 시스템)
|
다수의 사용자 요청을 여러 서버에 분산하여 서비스 지연 방지.
|
|
다수의 독립 서비스가 동시에 작동하는 SaaS 플랫폼
|
각 서비스 인스턴스에 부하 분산으로 안정성 확보.
|
|
AI/머신러닝 API 호출 서비스
|
대량의 AI 요청을 처리하기 위해 여러 모델 인스턴스로 분산.
|
|
멀티테넌트 클라우드 서비스
|
고객별 서비스 복제본에 요청을 적절히 분산.
|
기대 효과 (Benefits)
- 고가용성 (High Availability): 서비스 인스턴스 장애 시 다른 인스턴스로 자동 분산.
- 수평 확장성 (Horizontal Scalability): 사용자 요청 증가에 따라 서비스 인스턴스 동적 추가.
- 성능 향상 (Performance Boost): 다수 인스턴스를 활용한 동시 요청 처리.
- 유연성 (Flexibility): 서비스 복제본의 자유로운 배치와 분산.
- 비용 최적화 (Cost Optimization): 필요한 경우에만 인스턴스 추가, 불필요 시 제거로 자원 절약.
클라우드 버스팅 아키텍처 (Cloud Bursting Architecture)
개념 (Definition)
클라우드 버스팅 아키텍처(Cloud Bursting Architecture)란 온프레미스(내부 데이터센터)의 자원이 초과 사용될 때, 자동으로 클라우드 자원을 확장해 사용하는 하이브리드 클라우드 아키텍처이다.
즉, 내부 리소스가 부족할 때만 클라우드 자원을 일시적으로 확장(버스트 아웃, Burst Out)하고, 사용량이 줄면 다시 온프레미스 자원 중심으로 복귀(버스트 인, Burst In)하는 방식이다.
이를 통해 온프레미스 환경의 성능 한계를 보완하면서도 필요할 때만 클라우드를 활용해 비용을 절감할 수 있다.
클라우드 자원은 사전에 준비(배포)되어 있으나, 버스팅 발생 전까지는 비활성화(대기) 상태로 유지된다.
특히 일시적 트래픽 폭증, 예측 불가능한 부하 상황, 하이브리드 클라우드 환경에 최적화되어 있으며, 비용 절감, 성능 유지, 고가용성을 동시에 충족하는 클라우드 설계 방식으로 매우 유용하다.
- 버스트 아웃 (Burst Out): 온프레미스 자원 초과 시 클라우드 자원 활성화 및 부하 분산.
- 버스트 인 (Burst In): 부하 감소 시 클라우드 자원 해제 및 온프레미스 자원으로 복귀.
동작 방식 (How it Works)
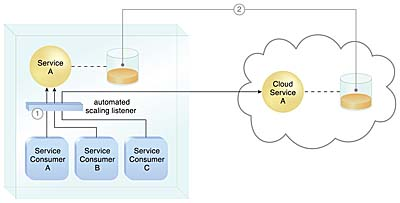
자동화된 스케일링 리스너는 온프레미스 서비스 A의 사용을 모니터링하고, 서비스 A의 사용 임계값이 초과되면 서비스 소비자 C의 요청을 클라우드(클라우드 서비스 A)의 서비스 A의 중복 구현으로 리디렉션한다. (1)
리소스 복제 시스템은 상태 관리 데이터베이스를 동기화 상태로 유지하는 데 사용된다. (2)
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
대규모 이벤트로 인해 일시적 트래픽 폭증
|
온프레미스 서버 용량 초과 시 자동으로 클라우드 자원으로 부하 분산.
|
|
내부 인프라 확장이 어려운 상황
|
클라우드 자원을 임시로 활용해 빠르게 확장.
|
|
주기적으로 부하가 집중되는 업무
|
예: 급여 계산, 세금 보고 등 대량 데이터 처리 시 일시적 확장.
|
|
비용 최적화
|
평소에는 온프레미스 자원만 사용, 트래픽 급증 시에만 클라우드 사용으로 비용 절감.
|
기대 효과 (Benefits)
- 성능 유지 (Performance Assurance): 트래픽 급증 시에도 서비스 중단 없이 부하 처리.
- 비용 절감 (Cost Efficiency): 평소에는 온프레미스 자원만 사용하여 고정 비용 절감.
- 유연성 (Flexibility): 필요 시 즉각적 확장 가능.
- 고가용성 (High Availability): 클라우드를 보조 자원으로 사용하여 장애 발생 시 복구 용이.
- 하이브리드 클라우드 환경 지원: 온프레미스 + 퍼블릭 클라우드 혼합 운영 가능.
탄력적 디스크 프로비저닝 아키텍처 (Elastic Disk Provisioning Architecture)
개념 (Definition)
탄력적 디스크 프로비저닝 아키텍처(Elastic Disk Provisioning Architecture)는 클라우드 스토리지 공간을 동적으로 할당하고, 실제 사용한 용량만 과금(pay-as-you-go)하는 클라우드 아키텍처이다.
전통적인 고정 디스크 할당 방식(Fixed-Disk Allocation)은 할당한 전체 디스크 용량에 대해 비용이 청구되지만, 탄력적 디스크 프로비저닝은 얇은 프로비저닝(Thin Provisioning) 기술을 사용하여 필요할 때만 저장 공간을 점진적으로 할당함으로써 비용 절감과 자원 효율성을 동시에 달성할 수 있다.
이를 통해 비용, 성능, 자원 사용량을 동시에 최적화할 수 있는 현대적 스토리지 관리 모델이다.
동작 방식 (How it Works)
이 아키텍처는 클라우드 소비자가 실제로 사용하는 정확한 스토리지 양에 대해 세부적으로 청구되도록 보장하는 동적 스토리지 프로비저닝 시스템을 구축한다.
이 시스템은 스토리지 공간을 동적으로 할당하기 위해 씬 프로비저닝 기술을 사용하며, 청구 목적으로 정확한 사용 데이터를 수집하기 위해 런타임 사용 모니터링으로 추가로 지원된다.
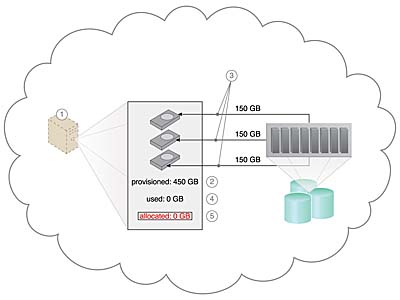
클라우드 소비자는 각각 150GB 용량의 하드 디스크 3개가 있는 가상 서버를 요청한다. (1)
이 아키텍처는 가상 서버에 총 450GB의 디스크 공간을 프로비저닝한다. (2)
450GB는 이 가상 서버에 허용되는 최대 디스크 사용량으로 설정되었지만 아직 물리적 디스크 공간이 예약되거나 할당되지 않았다. (3)
클라우드 소비자는 소프트웨어를 설치하지 않았으므로 실제 사용된 공간은 현재 0GB이다. (4)
할당된 디스크 공간이 실제 사용된 공간(현재 0)과 같으므로 클라우드 소비자는 디스크 공간 사용에 대해 요금을 청구받지 않는다. (5)
씬 프로비저닝 소프트웨어는 하이퍼바이저를 통해 동적 스토리지 할당을 처리하는 가상 서버에 설치되고, 사용량에 따른 요금 모니터는 세부적인 청구 관련 디스크 사용 데이터를 추적하여 보고한다.
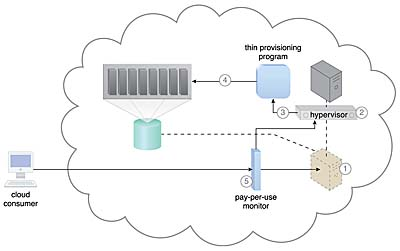
클라우드 소비자로부터 요청을 받고 새로운 가상 서버 인스턴스의 프로비저닝이 시작된다. (1)
프로비저닝 프로세스의 일부로 하드 디스크가 동적 또는 씬 프로비저닝 디스크로 선택된다. (2)
하이퍼바이저는 동적 디스크 할당 구성 요소를 호출하여 가상 서버에 대한 씬 디스크를 만든다. (3)
가상 서버 디스크는 씬 프로비저닝 프로그램을 통해 생성되어 거의 0 크기의 폴더에 저장된다. 이 폴더와 해당 파일의 크기는 운영 애플리케이션이 설치되고 추가 파일이 가상 서버에 복사됨에 따라 커지게 된다. (4)
사용량에 따른 요금 모니터는 청구 목적으로 실제 동적으로 할당된 스토리지를 추적한다. (5)
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
예상치 못한 데이터 저장량 변화가 있는 서비스
|
실제 저장 용량에 따라 비용 절감.
|
|
대규모 가상 서버 환경
|
필요 시에만 스토리지 확장, 자원 낭비 방지.
|
|
애플리케이션 초기 배포 시
|
미사용 공간에 대한 비용 절감, 초기 설치 최소 용량만 할당.
|
|
테스트/개발 환경
|
다양한 용량 설정에도 실제 사용 시점까지 자원 할당 보류.
|
기대 효과 (Benefits)
- 비용 최적화 (Cost Efficiency): 실제 사용한 용량만 과금, 불필요한 용량에 대한 과금 방지.
- 유연성 (Flexibility): 사용량 증가 시 자동 확장, 애플리케이션 성능 유지.
- 효율적 자원 활용 (Efficient Resource Usage): 미사용 자원의 낭비 방지.
- 자동화된 확장 (Automated Provisioning): 사용량 증가에 따라 자동 할당.
- 클라우드 서비스에 적합 (Cloud-Native): 대규모 다중 테넌트 환경에서 비용 및 자원 최적화.
기존 고정 디스크 방식과 차이
|
구분
|
고정 디스크 할당 (Fixed Disk)
|
탄력적 디스크 프로비저닝 (Elastic Disk)
|
|
디스크 용량 할당
|
미리 전체 할당
|
필요 시 동적 할당
|
|
과금 기준
|
할당된 전체 용량 기준 과금
|
실제 사용 용량 기준 과금
|
|
초기 비용
|
높음
|
낮음 (최소 자원 사용)
|
|
유연성
|
제한적 (미리 결정된 용량만 사용)
|
높음 (동적 확장 가능)
|
이중화 스토리지 아키텍처 (Redundant Storage Architecture)
개념 (Definition)
이중화 스토리지 아키텍처(Redundant Storage Architecture)는 클라우드 스토리지 장애 및 데이터 손실에 대비하기 위한 고가용성(High Availability) 아키텍처로, 주(primary) 스토리지 장치의 복제본(secondary storage)을 구축하여 실시간 동기화(Synchronous) 또는 비동기화(Asynchronous)를 통해 데이터를 이중화한다.
주 스토리지 장치가 장애 발생 시, 자동으로 보조 스토리지로 전환(Failover)되어 서비스 연속성(Continuity)을 유지한다.
클라우드 스토리지의 장애 대비, 데이터 복구, 고가용성을 위한 필수 아키텍처이다.
특히, 중단 없는 서비스 제공, 법적 요구사항을 충족하는 안전한 데이터 복제, 재해 복구 및 비즈니스 연속성 확보에 최적화된 구조로, 금융, 의료, 공공기관, 대규모 서비스 플랫폼에서 반드시 채택되어야 할 아키텍처 중 하나이다.
동작 방식 (How it Works)
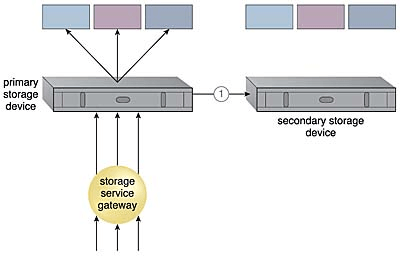
주 클라우드 저장 장치는 정기적으로 보조 클라우드 저장 장치로 복제된다. (1)
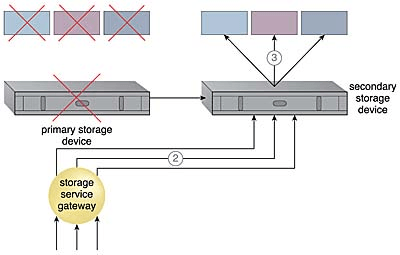
주 스토리지가 사용할 수 없게 되고 스토리지 서비스 게이트웨이가 클라우드 소비자 요청을 보조 스토리지 장치로 전달한다. (2)
보조 스토리지 장치의 논리 유닛 번호 (LUN, Logical Unit Number)를 이용해 클라우드 소비자가 데이터에 계속 액세스할 수 있도록 한다. (3)
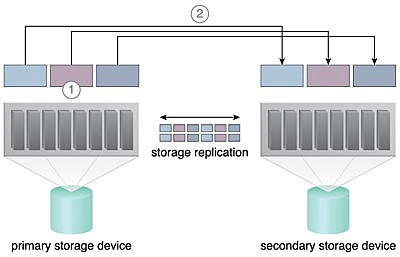
이중화 스토리지 아키텍처는 기본 클라우드 스토리지 장치를 복제된 보조 클라우드 스토리지 장치와 동기화 상태로 유지하는 스토리지 복제 시스템에 주로 의존한다.
적합한 사용 사례 (Use Cases)
|
상황
|
사용 이유
|
|
클라우드 기반 데이터베이스 운영
|
데이터 손실 방지 및 고가용성 확보.
|
|
대규모 클라우드 파일 저장소 서비스 (예: 영상, 이미지 서비스)
|
장애 시에도 데이터 지속 접근 보장.
|
|
금융, 의료 등 고가용성 필수 산업
|
무중단 서비스 운영 필요.
|
|
재해 복구(Disaster Recovery)
|
지역간 스토리지 복제 및 비상 상황 대비.
|
기대 효과 (Benefits)
- 고가용성 (High Availability): 주 스토리지 장애 시 보조 스토리지로 자동 전환.
- 데이터 안전성 (Data Safety): 지속적인 데이터 복제를 통해 데이터 손실 최소화.
- 비즈니스 연속성 (Business Continuity): 서비스 중단 없는 데이터 제공.
- 재해 복구 지원 (Disaster Recovery Support): 지역 간 데이터 복제로 비상 상황 대응.
- 성능 최적화 (Performance Optimization): 이중화 구성을 통해 로드 밸런싱 가능.
클라우드 스토리지 장치
클라우드 서비스 제공자가 인터넷을 통해 제공하는 가상 스토리지 서비스로 사용자가 직접 물리적 저장 장치를 소유하지 않고, 필요한 만큼 데이터를 저장하고 접근하는 서비스이다.
- 확장성, 고가용성, 보안성, 유연성을 제공하는 현대 IT 인프라의 핵심 자원
- 올바른 스토리지 선택을 위해서는 성능, 비용, 확장성, 데이터 접근 방식을 고려해야 함
클라우드 스토리지 유형 및 인터페이스 종류
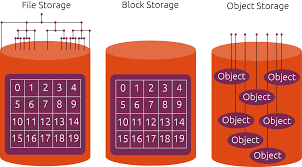
클라우드 스토리지는 객체 스토리지(Object Storage), 파일 스토리지(File Storage), 블록 스토리지(Block Storage)로 구분된다.
객체 스토리지
객체 스토리지는 데이터를 객체 단위(파일 + 메타데이터)로 저장하는 방식으로, 대용량 비정형 데이터 저장에 적합하다.
- 주로 REST API, S3 API, HTTPS, SDK와 같은 인터페이스를 통해 접근한다.
- 대표적인 사용 사례로는 데이터 백업, 이미지 및 동영상 저장, 빅데이터 분석, AI 학습 데이터 저장이 있다.
- 예시 서비스: AWS S3, Azure Blob Storage, Google Cloud Storage
파일 스토리지
파일 스토리지는 파일 시스템 기반으로 데이터를 파일 단위로 저장하고 여러 사용자가 공유할 수 있는 형태이다.
- NFS(Network File System), SMB/CIFS(Server Message Block), 파일 API 같은 인터페이스를 사용한다.
- 파일 서버, 협업 환경에서의 파일 공유, 콘텐츠 관리와 같은 사례에 주로 사용된다.
블록 스토리지
블록 스토리지는 데이터를 디스크 블록 단위로 저장하며, 데이터베이스나 고성능 워크로드에 적합하다.
- iSCSI, Fibre Channel, NVMe-oF, API (예: AWS EBS API) 같은 인터페이스를 사용한다.
- 데이터베이스 저장소, 가상 머신 디스크, 고성능 트랜잭션 처리 시스템에 활용된다.
- 예시 서비스: AWS EBS, Azure Disk Storage, Google Persistent Disk
데이터베이스 스토리지 인터페이스
데이터베이스 스토리지 인터페이스란 데이터베이스 관리 시스템(DBMS)이 데이터를 저장하고 읽고 쓰기 위해 스토리지와 연결하는 방식 또는 데이터 입출력 경로를 의미한다.
즉, 데이터베이스가 데이터 파일, 트랜잭션 로그, 인덱스 등을 저장하기 위해 스토리지 시스템과 직접 상호작용하는 기술적 수단이다.
- 최근 현대 애플리케이션 개발 환경에서는 데이터베이스 스토리지 인터페이스로 클라우드 스토리지 인터페이스(블록 스토리지)를 사용하는 경우가 많다. (과거에는 DAS 방식으로 직접 로컬 디스크를 연결하는 방식을 사용했다.)
- 예시1) Amazon RDS, Aurora → AWS EBS (Elastic Block Store) 사용
- 예시2) Azure SQL Database → Azure Managed Disks 사용
데이터베이스 스토리지 인터페이스의 주요 역할
- 데이터베이스 데이터 파일, 로그 파일, 인덱스 파일 저장
- 트랜잭션 처리, 동시성 제어, 데이터 무결성을 보장할 수 있는 스토리지 연결
- 데이터의 신뢰성, 고가용성, 고성능, 확장성을 보장
데이터베이스 스토리지 인터페이스의 구성 방식 (유형)
주로 블록 스토리지가 사용되며, 일부 파일 스토리지, 객체 스토리지도 목적에 맞게 사용된다.
특히 클라우드 환경에서는 블록 스토리지 인터페이스를 통한 데이터베이스 운용이 주류이며, 자동 확장, 고성능, 고가용성 지원이 강점이다.
- 로컬 스토리지 (DAS): 데이터베이스가 가장 빠르게 직접 디스크에 접근 가능, 단일 서버 중심
- 파일 스토리지 (NAS): 데이터베이스 파일 및 로그 파일 저장 가능 (일반적 파일 시스템 접근)
- 블록 스토리지 (SAN, iSCSI, NVMe-oF): 고성능 OLTP 데이터베이스에 적합, 로우 디스크 접근
- 객체 스토리지 (Object Storage): 데이터베이스 백업, 비정형 데이터 저장
클라우드 사용 모니터와 구성 요소
클라우드 사용 모니터 (Cloud Usage Monitor)
클라우드 자원의 사용량, 성능, 장애 여부 등을 실시간으로 수집/분석하는 시스템이다.
- 클라우드 환경에서 가상 머신, 스토리지, 네트워크, 애플리케이션 등 다양한 자원 사용 현황을 모니터링
- 클라우드 운영 효율화, 비용 절감, 장애 예방을 위한 핵심 도구
주요 기능
- 자원 사용량 모니터링 (CPU, 메모리, 네트워크, 디스크)
- 트래픽 및 성능 분석
- 장애 및 이벤트 알림 (Alert)
- 대시보드 및 시각화 제공
예시: AWS CloudWatch, Azure Monitor, Google Cloud Operations (formerly Stackdriver)
모니터링 에이전트 (Monitoring Agent)
모니터링 대상 서버나 자원에 직접 설치되어 동작하는 소프트웨어이다.
- CPU, 메모리, 네트워크, 애플리케이션 상태 등의 데이터를 주기적으로 수집하여 중앙 모니터링 시스템으로 전송
주요 역할
- 서버 내부 상태 정보 수집 (호스트 기반 모니터링)
- 애플리케이션 동작 상태 점검
- 모니터링 서버와 통신하여 데이터 전송
예시: AWS CloudWatch Agent (EC2 메트릭 수집), Prometheus Node Exporter, Zabbix Agent
자원 에이전트 (Resource Agent)
클라우드 자원(가상 머신, 스토리지, 네트워크 등)을 직접 제어/관리/감시하는 소프트웨어 컴포넌트이다.
- 모니터링뿐만 아니라 자원 상태 변경, 자동 복구, 배포 지원 등 제어 기능 포함
주요 역할
- 자원의 상태 확인 및 변경 (예: VM 시작/중지/재시작)
- 자원 이상 시 복구 또는 대체 자원 할당
- 자원 스케일링 및 자동화 지원
예시: Kubernetes Controller (Pod, Deployment 관리), OpenStack Nova Compute (가상 머신 제어), Pacemaker Resource Agent (HA 자원 관리)
폴링 에이전트 (Polling Agent)
네트워크나 시스템 자원의 상태를 주기적으로 요청(폴링)해서 점검하는 소프트웨어이다.
- 주로 네트워크 장비, 클라우드 API, 외부 서비스 상태 확인에 사용
주요 역할
- 주기적 상태 점검 (정기적 Ping, HTTP 요청 등)
- 모니터링 시스템에 결과 보고
- 장애 발생 시 알림 또는 자동 복구 트리거
예시: SNMP Poller (네트워크 장비 상태 체크), Nagios Polling Agent, Prometheus Polling Exporter
자원 복제 (Resource Replication)
클라우드 자원을 다른 지역(Region), 가용 영역(Availability Zone), 또는 다른 시스템에 동일하게 복사/동기화하는 작업이다.
- 데이터 무결성, 가용성, 재해 복구(Disaster Recovery, DR)를 위한 필수 기능
주요 역할
- 데이터 복제 (스토리지, 데이터베이스, 오브젝트 스토리지)
- 서버/애플리케이션 복제 (멀티 AZ, 멀티 리전 배포)
- 장애 시 대체 자원 활성화 (Failover)
예시: AWS S3 Cross-Region Replication (CRR), Azure Geo-Redundant Storage (GRS), Database Replication (MySQL, PostgreSQL 리플리케이션)
'Theory > Infrastructure & Network' 카테고리의 다른 글
| www.google.com 접속 통신 과정 (0) | 2025.03.11 |
|---|---|
| 네트워크 이론 (1) (0) | 2025.03.10 |
| 클라우드 컴퓨팅 이론 (2) (0) | 2025.03.08 |
| AWS, Azure, GCP 비교 요약 (1) | 2025.03.07 |
| 클라우드 컴퓨팅 이론 (1) (0) | 2025.03.06 |



