[AWS DVA-C02] 유데미 강의 압축 요약 정리본
IAM, AWS CLI, SDK, CDK
[IAM]
IAM 사용자 그룹에는 IAM 사용자만 포함 가능.
IAM 역할(Role) : AWS 서비스에서 다른 서비스로 접근할 때 필요한 IAM 엔터티
IAM 자격 증명 보고서(Credentials Report) : IAM 보안 도구 중 하나로, 모든 AWS 계정의 IAM 사용자와 다양한 자격 증명의 상태(암호, 액세스 키, MFA 디바이스 등) 확인할 수 있음
IAM Best Practice : 1:1 매칭(사람-IAM사용자), AWS 자격증명 공유 금지, 루트 계정 사용 금지, MFA 사용, 최소 권한 부여
AWS STS(Security Token Service) : 다른 AWS 계정에서 IAM 역할을 맡도록 승인된 AWS 계정에서 IAM 역할을 생성하여 교차 계정 액세스 권한 획득
IAM 정책(Policy) : IAM 정책은 AWS 서비스 사용을 위한 권한의 집합을 정의한 JSON 문서, IAM 사용자, 그룹, 역할에 부여해서 사용
- IAM 정책의 문장(Statement) 하위 구성 요소 : Sid(Statement의 ID), Effect(허용/차단 여부), Principal(정책이 적용될 대상), Action(권한), Resource(특정 리소스 지정) 및 Condition(조건)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowS3ReadOnlyFromSpecificIP",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/SpecificUser"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::example-bucket",
"arn:aws:s3:::example-bucket/*"
],
"Condition": {
"IpAddress": {
"aws:SourceIp": "203.0.113.0/24"
}
}
}
]
}- 관리형 정책 (Managed Policy)
- AWS 관리형 정책: AWS에서 제공하는 사전 정의된 정책 (예: AmazonS3ReadOnlyAccess)
- 고객 관리형 정책: 사용자가 만든 재사용 가능한 정책
- 특징: 여러 사용자/역할/그룹에 공통 적용 가능, 권한 변경 시 전체에 즉시 반영됨
- 인라인 정책 (Inline Policy) : 특정 사용자/역할에만 귀속되는 고립된 정책, 객체 삭제 시 정책도 함께 사라짐
- 서비스 제어 정책 (SCP)
- AWS Organizations 에서 설정, 계정이나 조직 단위로 최대 허용 가능 권한 제한
- 특징: IAM 정책 Allow여도, SCP에서 Deny면 실행 불가, Organization 단위 보안 제어 필수 요소
- 세션 정책 (Session Policy) : STS를 통해 임시 Role을 Assume할 때 전달되는 정책
- 리소스 기반 정책 (Resource-based Policy) : 리소스 객체에 직접 부착되는 정책 → S3, SNS, Lambda, API Gateway 등에 사용(cross-account 접근 제어에 필수)
- 퍼미션 경계 (Permissions Boundary) : IAM 역할 또는 사용자에 대해 "최대 권한 한도"를 정의하는 정책 (개발자가 IAM 역할을 만들어도, S3 FullAccess 같은 위험한 권한은 못 넣도록 제한 가능)
[AWS CLI]
- AWS CLI 런타임은 Python
- AWS CLI는 인스턴스 메타데이터를 활용해 임시 자격 증명을 얻음
- 인스턴스 메타데이터 서비스를 사용해 EC2 인스턴스에 연결된 IAM 역할 이름 조회 가능 단, IAM 정책 자체는 검색 불가
- 자격 증명 탐색 우선순위 : CLI Options → Environment Variable → EC2 Instance Profil
[SDK]
사용 사례
- 온프레미스 서버에서 버킷 접근 : IAM 사용자 생성 및 적절한 권한 할당 → 자격 증명을 환경 변수에 삽입
- 쓰로틀링 발생 : 지수 백오프(Exponential Backoff) 전략 (재시도 대기시간 지수 증가(1→2→4→…))
- MFA 설정된 API 사용 : STS API GetSessionToken
- AWS API 요청 서명 시 SigV4 사용
[CDK]
- 파이썬을 사용하여 AWS에서 인프라를 생성(CloudFormation 템플릿(JSON, YAML) 대안으로 사용)
EC2
스팟(Spot) 인스턴스 : 짧은 워크로드에 적합하며 가장 저렴한 구매 옵션, 안전성 부족(갑자기 중단됨)
예약(Reserved) 인스턴스 : 1년(3년)동안 실행할 계획인 애플리케이션에 적합한 구매 옵션
- 예약(Reserved) 인스턴스 기간 : 1년 또는 3년
전용(Dedicated) 인스턴스 : 강한 규정 준수 요구 사항 회사나 라이선스 모델(비용청구)이 복잡한 SW에 적합
인스턴스 최적화 모드 종류
- HPC : 컴퓨팅 최적화(Computing Optimization)
- 인메모리 DB 사용하는 중요 애플리케이션 : 메모리 최적화(Memory Optimization)
- OLTP DB 초당 수천 개 요청 들어오는 애플리케이션 : 스토리지 최적화(Storage Optimization)
보안 그룹(Security Group) : 인스턴스 수준에서 작동, Stateful(Session), 1:N 매칭(인스턴스-보안그룹)
사용자 데이터(User Data) : 부트스트랩 코드(SW, Package 설치 및 파일 다운로드 등 수행)
EBS
- 범위 : AZ
- 종료(Terminate) 시 삭제 속성 기본값 : 루트(활성화), 이외(비활성화)
- 부팅 볼륨 사용 불가 : st1, sc1
- 다중 연결 : 동일 AZ 내 여러 인스턴스가 동일 EBS 사용(모든 인스턴스는 읽기/쓰기 권한 보유)
- IOPS 성능 향상 : RAID 0 마운트, io 사용(io : 최대 256,000 IOPS), 볼륨 크기 확장(gp : 최대 16,000 IOPS, 5334GB)
AMI
- 범위 : 리전 (복제 가능, 복제 시 고유 ID 변경됨)
EFS
- 범위 : 리전 (서로 다른 AZ에 속한 인스턴스끼리 동일한 파일 시스템 탑재(NFS)
인스턴스 스토어 : 고성능 로컬 캐시, 최고의 DISK I/O 성능(io로 감당 안 되는 IOPS도 지원)
EC2 인스턴스에 대한 인스턴스 메타데이터 액세스 (curl 활용)
- Metadata : http://169.254.169.254/latest/meta-data/
- Dynamic Data : http://169.254.169.254/latest/dynamic/
- User Data(부트스트랩) : http://169.254.169.254/latest/user-data
ELB, ASG
Auto Scaling Group(오토 스케일링)
- 스케일업(수직 확장, 스펙 확장) ↔ 스케일다운(수직 축소, 스펙 축소)
- 스케일아웃(수평 확장, 인스턴스 수 확장) ↔ 스케일인(수평 축소, 인스턴스 수 축소)
- Health Check(EC2(기본값, 시스템 수준), ALB(애플리케이션 수준) 중 택1) → 비정상 시 종료 후 실행
- 대상 추적(Target Tracking) : 설정한 목표 지표(CPU 60%)에 맞춰 자동 조정
- 단계별(Step) : 지표 값이 특정 임계치 이상/이하일 때 트리거 발동 해 단계별로 자동 조정
- 쿨다운 : 스케일링 활동 후 인스턴스 조정 안함 (메트릭 안정화 시간, 기본값 300초)
NLB(Network Load Balancer)
- 고성능, 저지연, TCP/UDP, Sticky Session(소스 IP 해싱), Health Check(TCP(기본값), HTTP/HTTPS), 정적 DNS 주소 제공, 정적 IP 할당 가능(AZ당 1개), Cross-Zone Load Balancing(비활성화(기본값)), SNI 지원
ALB(Application Load Balancer)
- X-Forwarded-For(클라이언트 원본 IP), Sticky Session(쿠키), Health Check(HTTP/HTTPS), 정적 DNS 주소 제공, 동적 IP(재시작, AZ 변경 등으로 인해 변경됨), 라우팅 지원, Cross-Zone Load Balancing 지원(활성화(기본값)), SNI 지원
- Sticky Session을 위한 쿠키 예약어 : AWSALB, AWSALBAPP, AWSALBTG
- 라우팅 종류 : 경로, 호스트, HTTP Header, Query String, HTTP Method, Source IP. (복합 사용 가능)
Cross-Zone Load Balancing : AZ 기준이 아니라 인스턴스 기준으로 균등하게 분산
SNI : 클라이언트가 서버에 TLS 핸드셰이크를 시작할 때 접속하려는 호스트 이름(도메인)을 명시적으로 전달 → 클라이언트의 정보를 참고해 서버가 적절한 인증서 반환(멀티 도메인, SSL 인증서 구성 용이)
RDS, Aurora, ElastiCache
RDS
- 지원하는 DB 엔진 : MySQL, PostgreSQL, MariaDB, Oracle, MSSQL, Amazon Aurora(호환 엔진 : MySQL, PostgreSQL)
- DR(재해 복구) : Multi AZ 활성화(리전 단위 재해 대비 X), CRR(Cross-Region Replication), Backup
- 고가용성 : Multi AZ 활성화(동기식 복제), 이중화, Auto Scaling
- 읽기 트래픽 전략 : ElastiCache 클러스터, Read Replica(비동기식 복제, 최종 일관성 보장, 복제본마다 DNS 주소 제공, 분석 쿼리에 적합, 복제본도 Multi AZ 가능, 최대 15개)
- IAM DB 인증 : IAM 사용자로 DB 인스턴스 액세스 권한 부여(Oracle 지원X)
- 암호화되지 않은 DB 암호화 : 스냅샷 생성 후 복사 → 암호화 활성화 → 암호화된 스냅샷으로 재생성
Elastic Cache
- 세션 데이터 저장(Sticky Session 대체)
- Redis Cluster 최대 개수 : 5개
- 캐시 제거(Cache Eviction) : 만료(TTL) 전에 캐시에서 데이터가 제거되는 현상 → ElasticCache Redis 클러스터의 인스턴스 크기 확장, 샤드 수 증가
Cache 전략
- Write Through : Write 요청마다 캐시에 즉시 반영 → 캐시 일관성 높음 (DB와 동기화), DB + 캐시에 모두 Write(이중 작업) → 대부분 캐시 히트 (자주 사용하지 않는 데이터도 캐시에 적재됨)
- Lazy Loading : Read 요청에만 캐시에 적재 → 캐시-DB 간 일관성 관리 필요, DB에만 Write(캐시는 읽기 시에만 Write), 첫 읽기는 캐시 미스, 이후 캐시 히트 (자주 사용되는 데이터만 캐시에 적재됨)
RDS와 Amazon Aurora의 차이점 : RDS는 다양한 DB 엔진(MySQL, PostgreSQL 등)의 표준 버전을 관리형으로 제공하고, Aurora는 AWS가 개발한 고성능·고가용성 전용 엔진을 MySQL 또는 PostgreSQL과 호환되게 제공하는 서비스
Route 53
DNS 레코드 사용 사례
- ALIAS : 도메인 연동
- CNAME : 서브 도메인
- NS : 네임서버
DNS 라우팅 정책
- 가중치(weight) : 백분율 기반 트래픽 리디렉션
- 지연시간(latency) : 사용자 ↔ AWS 리전 간 지연 시간 최소화
- 지역(Geolocation) : 국가별 액세스 제어
도메인 위임 사례 (도메인 구매한 곳 → NS 레코드 추가 / 도메인 서비스 공급하는 곳 → Zone 생성)
- 서드파티 도메인 구매(NS 레코드 값 : Route 53 서버), Route 53 서비스 공급자(퍼블릭 호스팅 영역 생성)
VPC
SG : EC2 인스턴스 수준 ↔ NACL : 서브넷 수준
NAT GW : 프라이빗 서브넷의 인스턴스가 인터넷 사용 시 활용 가능 (AWS Managed)
VPC GW Endpoint 지원 : S3 & DynamoDB ↔ 이외 서비스는 Interface Endpoint(PrivateLink 활용)
VPC Flow Logs : VPC의 NIC 트래픽(인/아웃바운드 모두) 캡처
Direct Connect : 온프레미스 DC ↔ AWS 클라우드 간 전용 비공개 연결
S3
주의사항(참고사항)
- 파일 업로드 시 100MB 초과하면 멀티파트 업로드 권장
- 버킷 이름은 전역 고유
- 기존에 생성되어 있던 파일들은 버전 관리 활성화 시 null (이후 v1, v2, v3, …)
- IAM 정책(AWS 리소스 단위)과 버킷 정책(개별 버킷 단위) 동시에 사용 가능(둘 중에 하나라도 Deny면 차단)
- 버킷마다 CORS 설정 필요
- 암호화 방식 SSE-C, 사용 시 HTTPS 사용 필수 (고객 제공 암호화 키 전달을 위함)
- MFA 삭제 + 버전 관리를 통해 영구 삭제 방지
- 직원들 몰래 액세스 로그 확인 → S3 액세스 로그 활성화 + Athena 쿼리
- S3 Pre-Signed URL 로 S3 버킷 특정 위치로 임시 액세스 가능
- EC2 인스턴스 IAM 정책 + S3 정책은 동시에 사용할 수 있고, 교차평가 됨. 교차평가 방식 : 둘 중 하나라도 Allow 되어있지 않으면 접근 거부 다만, S3 정책에서 Public Read Access를 허용한 경우에는 정상 접근 가능함. 즉, 교차평가는 S3 버킷 정책에서 인증된 주체를 요청하는 경우에만 동작함. Principal: * 의 경우, 별도에 인증 주체를 요청하지 않음.
S3 TA + 멀티파트 업로드 조합 : 대역폭 양호, 인터넷 연결 안정적이지 않을 때 유용
S3 복제 : 다른 AWS 리전에서 해당 버킷을 사용하고 싶을 때 사용함. (데이터 분석 등)
S3 Glacier 검색 모드(Retrieval Modes)
- S3 Glacier(Standard, Flexible Retrieval) : Expedited (신속, 1~5분), Standard (표준, 3~5시간), Bulk (대량, 5~12시간, 최대 48시간))
- S3 Glacier Deep Archive : Standard (표준, 12시간 이내)
S3 이벤트 알림(S3 Event Notification) : 버킷 관련 특정 이벤트(객체 업로드, 삭제 등) 발생 시 알림
S3 LifeCycle(수명 주기)
- 이전(Transinition) : 일정 기간이 지난 객체를 다른 스토리지 클래스로 이동
- 만료/삭제(Expiration) : 지정한 날짜 또는 기간이 지나면 객체를 자동 삭제
S3를 활용한 파일 인덱스(메타데이터) : S3 Byte Range Fetches 실행 → RDS에 저장
S3 Select : S3 객체(예: CSV, JSON, Parquet) 전체를 다운로드하지 않고 필요한 데이터(특정 행, 열, 조건 등)만 추출(Query)
S3 암호화 방식
- SSE-S3 : S3가 자체적으로 관리하는 암호화 키(AES-256)를 사용해 서버 측에서 객체를 자동 암호화/복호화
- SSE-KMS : AWS KMS(Key Management Service)에서 관리하는 사용자 지정 키(CMK)로 S3 서버 측 암호화/복호화 (유일 암호화 키 순환 정책)
- SSE-C : 고객이 직접 제공한 암호화 키(HTTPS 필수)로 S3 서버 측에서 암호화/복호화 수행
- CSE : 클라이언트(사용자 측)에서 데이터 암호화 후 암호화된 상태로 S3에 저장
CloudFront
CF Pre-Signed 설정 시 CloudFront 키 페어(CF 자체 키)보다 신뢰할 수 있는 키 그룹(KMS 기반) 사용 권장
CF Pre-Signed URL : 주로 동적으로 생성된 서명된 URL을 통해 유료 콘텐츠를 배포하는 데 사용(개별 파일)
CF Pre-Signed Cookie : 주로 여러 파일에 액세스할 때 사용
CF Geo Restriction : 특정 국가 사용자만 허용하고 다른 국가는 차단
사용자가 CF를 통해서만 S3 액세스 : CF 배포 구성 → OAI 생성 → S3 Policy 업데이트(OAI만 허용)
CF Invalidation(무효화) : 새로운 정적 데이터를 배포했을 때 사용 (업데이트)
CF vs CRR : CF는 정적 컨텐츠 위주, CRR은 동적 컨텐츠 위주 저지연 시간 보장 (멀티 리전 복제가 동적 컨텐츠에 효과적)
CF 기반 캐시 종류 : HTTP 헤더, 쿠키, Query String
ECS, ECR, Fargete
ECS 시작 유형(Lanuch Type) : EC2, Fargate
ECS + Fargate : 서버를 관리하지 않고도 AWS에서 컨테이너를 실행
ECS 태스크 역할 : ECS 작업 자체에서 사용하는 IAM 역할, 컨테이너가 S3, SQS 등과 같은 다른 AWS 서비스를 호출하려고 할 때 사용 (/etc/ecs/ecs.config → EC2_ENABLE_TASK_IAM_ROLE 설정)
ECS에서의 EC2 인스턴스 프로파일 : EC2의 ECS 에이전트가 ECR에서 Docker 이미지를 가져오고 CloudWatch Logs에 컨테이너 로그를 저장하는 것과 같은 ECS 관련 작업을 실행하는 데 사용하는 IAM 역할
ECS에서의 EFS : 컨테이너의 영구 다중 AZ 공유 스토리지
ECR : 컨테이너 이미지를 쉽게 저장, 관리, 공유 및 배포할 수 있는 완전 관리형 컨테이너 레지스트리
ECR + CodeBuild 권한 문제 : AWS CodeBuild 서비스에 대한 IAM 역할 및 권한 재확인 필요
ECS 클러스터 임의의 호스트 포트 활성화 : Host Port = 0(또는 비어 있음)으로 설정해 동일한 유형의 여러 컨테이너를 동일한 EC2 컨테이너 인스턴스에서 시작할 수 있음.
ECS 작업 배치 전략 (Placement Strategy)
- spread : 작업을 가능한 고르게 분산시킴 (예시 : attribute:instanceId 기준으로 각 인스턴스에 균등하게 분산 배치)
- binpack : 하나의 인스턴스를 최대한 꽉 채운 후 다음 인스턴스로 배치 (예시 : cpu 또는 memory 기준으로 사용률이 가장 낮은 인스턴스에 우선 배치하여 비용 절감)
- random : 배치 대상 인스턴스를 무작위로 선택함 (특별한 최적화 없이 균일하게 임의 배치)
ECS 작업 배치 제약 조건(Placement Constraint)
- distinctInstance : 작업(Task)을 서로 다른 EC2 인스턴스에 배치하도록 강제 (같은 서비스의 작업이 동일 인스턴스에 배치되지 않음)
- memberOf : 커스텀 조건에 따라 작업을 배치 (예: 특정 인스턴스 속성 기반 조건 (attribute:ecs.instance-type == t3.medium), 표현식 사용 가능(attribute:environment != test))
작업 배치 전략 + 작업 배치 제약 조건을 활용해 배치 로직을 정교화 할 수 있음.
AWS Elastic Beanstalk (내부적으로 CloudFormation로 동작)
특정 언어 런타임 미지원 시 : EC2 부트스트랩 사용 (스크립트 + 보안 SW 설치)
EB 복제 기능 제공(테스트 환경 구축 시 사용), EB에서 사용한 RDS DB 유지하고 싶으면 별도로 스냅샷 필요.
EB + ElastiCache 연동 방법 : .ebextensions 폴더 → elasticcache.config 파일 설정
EB + HTTPS 설정 방법 : .ebextensions 폴더 → securelistener-alb.config 파일 설정
EB + X-Ray 연동 방법 : .ebextensions 폴더 → xray-daemon.config 파일 설정
EB의 배포 프로세스 개선법 : 사전 종속성 해결 + Beanstalk의 Zip 파일로 패키징
EB의 수명주기 정책 : 애플리케이션 버전 정리 자동화 기능 (오래되었거나 사용되지 않는 애플리케이션 버전을 자동으로 삭제 → S3 저장 공간 확보)
Elastic Beanstalk 배포 옵션(Deployment Options)
- All at Once : 모든 인스턴스에 동시에 새 애플리케이션 버전을 배포, 배포 속도가 가장 빠르지만, 배포 중 서비스가 일시 중단될 수 있음.
- Rolling : 일부 인스턴스씩 순차적으로 새 버전을 배포, 배포 중에도 나머지 인스턴스는 요청을 처리하므로 서비스 중단을 최소화할 수 있음.
- Rolling with Additional Batch : 임시 인스턴스를 추가하여 새 버전을 배포한 후, 기존 인스턴스를 순차적으로 교체, 무중단 배포가 가능하며 기존 인스턴스가 계속 요청을 처리함.
- Immutable : 기존 인스턴스는 그대로 두고, 새 Auto Scaling Group을 생성하여 전체 배포 후 정상 확인 시 교체, 무중단 배포 및 자동 롤백 지원, 다만 리소스 사용량이 증가함.
- Blue/Green : 별도의 환경(Environment)에 새 버전을 배포하고, 테스트 후 기존 환경과 CNAME 스왑으로 전환, 배포 전 검증 및 신속한 롤백이 가능, 하지만 두 환경 운영으로 비용 증가.
- Traffic Splitting (Canary) : 전체 트래픽 중 일부만 새 버전에 전달한 뒤, 이상 없으면 점진적으로 전체 트래픽 전환, 점진적이고 안정적인 배포가 가능, CodeDeploy 통합 필요.
AWS CloudFormation
CF ↔ Amazon S3 관계 : S3에 업로드된 템플릿을 참조. (CF 콘솔에서 업로드 시 S3에 저장)
CF 스택 업데이트 방법 : CF 템플릿 로컬에서 업데이트 → 업로드 및 적용
[AWS CloudFormation 주요 기능 정리]
- 스택(Stack) : CloudFormation 템플릿을 실행하여 생성된 리소스들의 논리적 집합. (생성/변경/삭제 작업은 스택 단위로 수행됨.)
- 스택셋(StackSets) : 하나의 템플릿으로 여러 AWS 계정 및 리전에 동시에 스택을 배포할 수 있는 기능. (조직 단위 또는 계정 리스트 기반 배포 가능)
- Change Sets (변경 세트) : 기존 스택에 변경 적용 전, 어떤 리소스가 어떻게 변경될지 사전 확인할 수 있음. (운영 중인 인프라에 영향을 주기 전에 변경 사항을 시각적으로 검토 가능.))
- Stack Updates (스택 업데이트) : 템플릿 수정 후 재배포하면 자동으로 변경된 리소스만 업데이트함. (무중단 배포 전략과 연계 가능.)
- Stack Rollback (스택 롤백) : 스택 생성 또는 업데이트 중 오류 발생 시 자동으로 이전 상태로 복구함. (안정성 확보를 위한 핵심 기능.)
- Drift Detection (드리프트 감지) : 실제 리소스 상태와 템플릿 정의가 불일치하는지 감지함. (수동 변경 여부를 확인하고 일관성 유지에 도움.)
- Stack Policies (스택 정책) : 스택 리소스에 대한 업데이트 제한을 정의함. (특정 리소스는 수정되지 않도록 보호 가능 (예: RDS 삭제 방지 등)).
- Nested Stacks (중첩 스택) : 템플릿을 모듈화하여 재사용 가능. (대규모 인프라를 계층적/구조적으로 관리할 수 있음.)
- Outputs / Parameters / Mappings / Conditions : 템플릿의 유연성 증가를 위한 구성 요소 Outputs : 다른 스택이나 사용자에게 출력할 값 Parameters : 사용자 입력값으로 템플릿 동적 설정 Mappings : 키-값 기반 정적 조건 매핑 Conditions : 조건부 리소스 생성 제어 *Pseudo Parameters : AWS에서 제공하는 변수(Region, AccountId, StackName, Partition 등)
- Resource Import : 기존 리소스를 CloudFormation 스택에 포함시켜 관리 가능. (즉, 리소스 수동 생성 후에도 자동화 관리로 편입 가능.)
- 내보내기(Export) : 스택의 출력값(Outputs)을 외부 스택에서 참조할 수 있도록 공개(export)하는 기능. (다른 스택에서 ImportValue로 사용할 수 있도록 공유 가능한 이름(리전 내 고유)을 지정해야 함)
- 임포트 값(ImportValue) : 다른 스택에서 Export 한 출력을 현재 스택에서 참조(import) 하는 기능, (스택 간 리소스 재사용 또는 참조 관계를 구성할 때 사용됨)
- !Ref 내장 함수 : CF 템플릿에서 리소스 또는 파라미터의 고유 식별자(ID, 값)를 참조하기 위한 내장 함수.
[AWS CloudFormation 주요 오류 발생 시 대처 정리]
- ROLLBACK_COMPLETE : 실패한 스택 삭제 후 새 스택 생성
- CloudFormation 스택을 삭제하려고 하지만 다른 CloudFormation 스택이 내보낸 출력을 참조하기 때문에 삭제할 수 없습니다. : Export(출력)을 참조하는 다른 CF 스택을 먼저 삭제
SQS, SNS, Kinessis
[SQS]
SQS는 별도 Auto Scaling을 활성화 할 필요 없음.
SQS 메시지 크기 제한(256KB)보다 더 큰 메시지 보내려면 SQS 확장 클라이언트 라이브러리 사용
SQS Queue 종류
1. 표준 큐(Standard Queue)
- 특징 : 기본 큐 타입, 높은 처리량과 최대 전달 보장(at-least-once) 제공
- 순서 보장 : 안 됨 (메시지는 중복되거나 순서가 바뀔 수 있음)
- 기대 효과 : 높은 확장성과 유연성 (대규모 백엔드 처리, 비순차 메시지 처리, 웹 훅 수집 등)
2. 지연 큐(Delay Queue)
- 특징 : 메시지를 일정 시간(delay) 동안 보이지 않게 큐에 보관
- 설정 방법 : 큐 레벨 또는 메시지 레벨에서 DelaySeconds 설정 (최대 15분)
- 기대 효과 : 지연된 메시지 전달 제어(메시지 처리 지연이 필요한 예약 작업, 재시도 대기 등)
3. FIFO 큐(First-In-First-Out Queue)
- 특징 : 정확히 한 번 처리(Exactly-once) 및 엄격한 순서 보장 제공, 메시지 그룹(MessageGroupID)만큼 소비자수 설정 가능
- 메시지 그룹 ID : 동일 그룹 ID 내 메시지 순서 보장
- 제한사항 : 처리량 제한 있음 (300 msg/sec, batching 사용 시 3,000 msg/sec) (거래 처리, 은행 시스템, 주문 처리 등 순서 중요 서비스)
4. 배달 못한 편지 큐(Dead Letter Queue, DLQ)
- 특징 : 메시지가 임계값만큼 반복 시도해 정상 처리되지 못할 경우, 이동되는 큐
- 연결 방식 : DLQ는 표준 큐 또는 FIFO 큐에 연결됨
- 제어 항목 : MaxReceiveCount 설정을 통해 몇 번 실패 후 DLQ로 이동할지 결정 (장애 진단, 오류 메시지 보관, 재처리 분석)
SQS의 설정 값
- Visibility Timeout : 다른 소비자가 메시지를 재수신 및 처리하지 못하는 기간 (기본값 : 30초, 최대 : 12시간) → 늘리면 메시지의 중복 읽기 방지 가능
- Delay Seconds(SQS 지연 큐에 활용) : 소비자에게 보이지 않는 새 SQS 메시지를 유지하는 기간 (기본값 : 0초, 최대 : 15분) → 처음에 큐에 인입됐을 때 메시지 숨기기
- MessageDeduplicationId : 동일한 중복 제거 ID를 가진 메시지가 전달되는 것을 방지 (기본값 : 5분)
- MessageGroupId : 한 그룹에 여러 메시지를 순서대로 처리할 수 있는 SQS FIFO 메시지 속성
- 메시지 보존기간 : 1분 ~ 14일 설정 가능 (기본값 : 4일)
- ReceiveMessageWaitTimeSeconds 값을 낮게 설정한 경우 빈 메시지 값을 받게 되는 경우 발생 → Long Polling 활성화(최대 : 20초)해 해결 가능.
[SNS]
SNS 메시지 필터링 : 특정 구독자(Sub)에게만 일부 메시지 전송 (필터링)
알림(HTTP(S), SQS, Lambda, 모바일 푸시, 이메일 또는 SMS 엔드포인트)에 주로 사용됨.
SNS + SQS Fan-Out : SNS Pub → Sub으로 여러 SQS Queues 등록해 처리 (SQS 큐를 추가해 더 많은 애플리케이션을 추가할 수 있어 확장성 우수)
[Kinessis] Producer(데이터 생산자) / Consumer(데이터 분석 처리 주체) / Shard(데이터 파티션 단위)
Kinesis Data Streams + Kinesis Data Firehose(AWS Lambda 연동 변환 처리 지원) = S3 및 Redshift에 실시간 데이터 로드할 때 적합
Kinesis Data Streams(Kinesis Data Analytics를 기본 데이터 소스로 사용 지원해 스트림에 대한 실시간 분석에 유리함)
Fan-Out(기본 Fan-Out) : 모든 소비자가 하나의 공유된 2MB/s 처리량을 보장받음
Enhanced Fan-Out(향상된 Fan-Out) : 각 소비자가 독립된 2MB/s 처리량을 보장받음
Kinesis Data Stream 기록 유지 기간 : 최대 365일
[Kinessis Data Stream 주요 오류 발생 시 대처 정리]
- ProvisionedThroughputExceededException : AWS Support 문의 (용량 확보) / 더 많은 샤드 확보(용량 제한은 데이터 스트림 내의 샤드 수로 정의, 샤드당 들어오는 데이터 1MB/s, 나가는 데이터 2MB/s 제한) / Shard Splitting(하나의 샤드를 두 개의 새로운 샤드로 나눠 쓰기 처리량 2배 확보)
- Kinesis 데이터 스트림으로 수집된 개별 사용자의 데이터가 여러 샤드에 분산되어 있고, 정렬되어 있지 않을 때 해결법 → 사용자의 ID를 파티션 키로 사용 (동일한 샤드로 맵핑됨)
CloudWatch, X-Ray, CloudTrail
[CloudWatch] : 애플리케이션을 모니터링하고, 시스템 전체의 성능 변화에 대응하고, 리소스 사용률을 최적화하고, 운영 상태에 대한 통합 보기를 얻을 수 있는 모니터링
CloudWatch 지표 수집 간격 : 기본 모니터링(5분), 세부 모니터링(1분)
고해상도 매트릭 알람 : 10초, 30초, 혹은 정기 알람을 60초의 배수로 설정 가능
CloudWatch Metric 활용 사례
- CloudWatch 사용자 지정 지표로 Backend ↔ DB 간 연결에 대한 분당 요청 수 기준 ASG와 연동
- CPU 제외 다른 컴퓨팅 자원 수집 시 에이전트 설치 필요
CloudWatch Logs : AWS 리소스(AWS Lambda, EC2, ECS 등)에서 생성된 로그 데이터를 수집·저장·모니터링하는 서비스
- Log Group : 동일한 로그 유형을 논리적으로 묶은 단위 (각 Log Group은 보존 기간 및 권한 설정 단위) (예: /aws/lambda/my-function, /ecs/my-service)
- Log Stream : Log Group 내에서 개별 리소스 인스턴스의 로그 흐름을 의미 (예: Lambda 실행 ID, EC2 인스턴스 ID 등으로 식별됨)
- 로그 보존 정책 (Retention Policy) : Log Group마다 로그 데이터를 얼마나 오래 보관할지 기간을 설정, 설정된 기간이 지나면 자동 삭제됨, (기본값 : 무제한 보존, 명시적으로 설정하지 않으면 삭제되지 않음)
- 저장된 기존 로그 암호화 API : Associate-kms-key
CloudWatch API & CLI
- PutMetricData : 사용자 지정 지표 데이터를 CloudWatch에 푸시
- set-arm-state CLI : CloudWatch 경보 테스트
[CloudTrail] : AWS 인프라 전반에서 작업과 관련된 계정 활동을 기록 및 모니터링
CloudTrail Insight : AWS 계정에서 비정상적인 활동 자동 감지 (머신러닝 기반 학습)
[X-Ray] : 애플리케이션에 대한 교차 계정 추적 및 시각화를 제공
Amazon X-Ray 이해하기
- X-Ray로 서비스 통합 간 발생한 문제 위치 감지 가능, 예) API GW + Lambda + DynamoDB 연동 후 문제
- 트레이스(Trace) : 하나의 클라이언트 요청(Request)에 대한 전체 호출 흐름을 추적하는 단위 (여러 서비스/리소스 간에 걸쳐 있는 요청의 연결된 실행 흐름)
- 세그먼트(Segment) : Trace를 구성하는 하위 작업 단위로, 개별 서비스 또는 컴포넌트에서 수행되는 작업 (애플리케이션, DB 호출, 외부 API 요청 등 단일 컴포넌트 단위)
- 하위 세그먼트(Subsegment) : 하나의 Segment 안에서 발생한 세부 작업 단위로, 성능 병목 지점, 오류 위치 등을 보다 세밀하게 분석할 수 있도록 지원(예: SQL 쿼리, HTTP 호출 등)
- 어노테이션(Annotation) : 세그먼트에 메타데이터 추가 (이를 활용해 세밀한 분석 가능)
- X-Ray Daemon 실행 중인지 확인 필수, X-Ray Daemon 구성을 위해 IAM 역할 생성 필수(중앙 AWS 계정으로 여러 AWS 계정 데이터 수집을 위해)
X-Ray SDK
- 초당 들어오는 요청의 약 5%에 대해서만 트레이스를 수집 및 전송(샘플링 비율)
X-Ray API
- BatchGetTraces : 여러 개의 트레이스 ID(trace ID)를 지정하여 해당 트레이스들의 전체 세부 정보(segments 포함)를 한 번에 조회하는 API
Lambda
[Lambda 기본 기능]
- Lambda의 환경 변수 : 코드를 업데이트하지 않고도 함수의 동작을 조정
- Lambda 버전 : 함수 코드 + 환경 구성을 불변(immutable) 상태로 고정하기 위해 버전별로 스냅샷으로 백업돼 있음.
- Lambda Alias : AWS Lambda 함수의 버전(version)에 고정된 별칭(name)을 부여해, 버전을 추상화하고 관리 및 배포를 유연하게 하는 기능
- Lambda 이벤트 소스 매핑(Event Source Mapping) : 이벤트 소스(예: SQS, DynamoDB, Kinesis 등)로부터 자동으로 이벤트를 가져와 Lambda 함수를 호출하게 연결하는 구성 요소
- Lambda Layer : 공통 라이브러리, 설정 파일, 코드 등을 재사용 가능하게 패키징하여 여러 함수에 공통으로 참조할 수 있도록 제공하는 배포 단위
- Lambda 리소스 기반 정책 : 외부 서비스나 다른 AWS 계정이 Lambda 함수를 호출할 수 있도록 권한을 부여하는 정책
- Lambda 목적지(Destinations) : Lambda 함수 실행 결과(성공 또는 실패)에 따라 후속 작업을 자동으로 전달할 수 있도록 구성하는 기능 (비동기 호출에만 적용 가능, 예시) S3 ↔ Lambda, EventBridge ↔ Lambda)
[Lambda 조합]
- Lambda + ALB : TG에 Lambda 추가
- Lambda + DLQ : 실패한 메시지를 며칠 동안 보관(=문제 해결을 위해 이벤트 수집, 분석 시 용이)
- Lambda + CloudWatch Events : 매 시간 호출되도록 구성(Schedule 기능)
- Lambda@Edge : CF 배포에 대한 요청이 AWS Edge 로케이션에서 필터링되도록 Lambda 함수를 전역으로 배포
- Lambda + CF Template : 모든 코드를 .zip 파일로 S3 업로드 → AWS::Lambda::Function 블록 객체 참조
[Lambda Spec]
- /tmp(512MB, 임시 파일 저장에 사용)
- 제한 시간 (최대 15분)
- ZIP 파일의 업로드 크기가 50MB로 제한
- 환경변수 4KB 제한 (4KB 초과 시 배포 패키지 .zip 파일에 포함해야 함)
[Lambda 관련 로그 해석]
- CloudWatch의 중복 요청 ID 로그 : Lambda 함수 실패로 인한 재시도
[Lambda 주요 오류 발생 시 대처 정리]
- Lambda 함수 관련 종속성 오류 : 함수 + 종속성을 하나의 폴더에 넣고 함께 압축
- 1시간 이상 걸리는 워크로드로 인해 시간 초과(Timeout) : 다른 서비스 사용(Lambda는 단기적인 워크로드에 적합)
- Lambda + 다른 서비스 연동 시 자주 발생 오류 : Lambda 함수 실행 역할 권한 부족. (S3의 경우, 버킷 정책에서도 허용 필수)
- UpdateFunctionCode 호출 중 InvalidParameterValueException 오류 : ZIP 파일의 크기가 50MB 초과 → S3에 업로드하는 대안이 있음.
- CF 템플릿에서 S3에 저장된 Lambda 코드를 참조하는 구조에서, Lambda 함수의 코드를 업데이트한 후 S3에 업로드했지만 함수가 업데이트되지 않음. → S3ObjectVersion 를 업데이트
DynamoDB
[DynamoDB 개요]
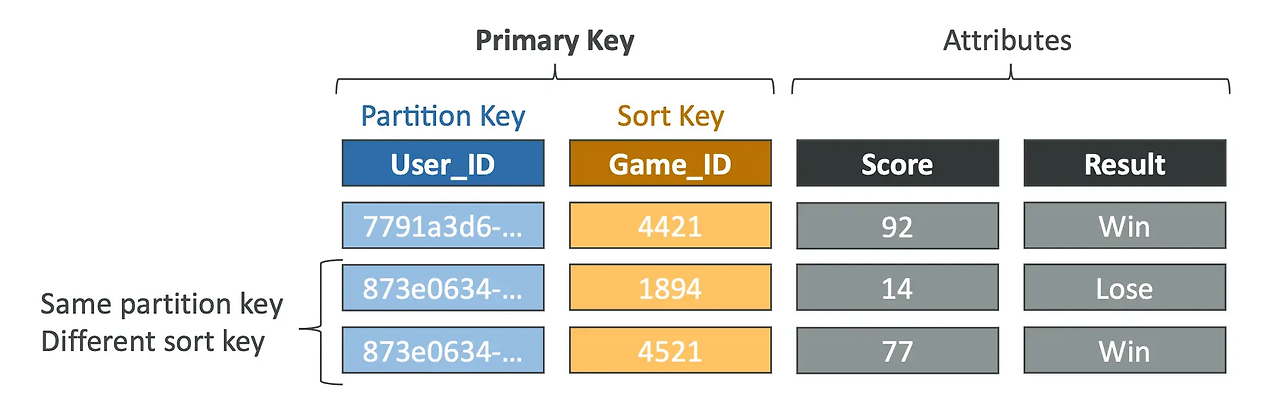
- Primary key와 Partition Key : cardinality(전체 행에 대한 특정 컬럼의 중복 수치)가 높은 것을 선택
- Scan : 테이블의 모든 항목을 순차적으로 읽어옴. (제어된 범위, 백엔드 작업)
- Query : Partition Key를 사용하여 값을 읽어옴. (실제 서비스)
- TTL : 테이블에서 만료된 항목을 자동 제거. (TTL 만료 후 48시간 이내 자동 삭제됨)
- 테이블 항목의 최대 크기 : 400KB
[DynamoDB WCU 및 RCU - 처리량]
- DynamoDB는 고성능 NoSQL 서버리스 데이터베이스로, 프로비저닝 모드 사용 시 처리량을 RCU/WCU 단위로 예약해야 하고 필요에 따라 Auto Scaling 활성할 수 있음(예약된 처리량), 온디멘드 모드 사용 시 처리량에 따라 Auto Scaling(간헐적인 요청, 비예측된 처리량)
- RCU (Read Capacity Unit) : 1초에 4KB 크기의 아이템을 1회 강하게 읽기(Strongly Consistent Read)할 수 있는 처리량 단위
- 약한(최종 일관성) 읽기(Eventually Consistent Read)의 경우 RCU 절반만 사용됨 (→ 4KB = 0.5 RCU)
- 트랜잭션 읽기(Transaction Read)는 2배 사용 (→ 4KB = 2 RCU)
- WCU (Write Capacity Unit) : 1초에 1KB 크기의 아이템을 1회 쓰기(Put, Update, Delete)할 수 있는 처리량 단위
- 쓰기(Write)의 경우 WCU 1개의 크기만 사용됨 (→ 1KB = 1 WCU)
- 트랜잭션 쓰기(Transaction Write)의 경우, 2배 사용됨. (→ 1KB = 2 WCU)
- NoSQL DB에서의 파티션 키 : NoSQL 에서 데이터를 물리적으로 분산 저장하고 조회 성능을 최적화하기 위한 핵심 키, ****데이터를 샤드 또는 파티션 단위로 분산할 때 사용됨.
[DynamoDB 인덱스(GSI + LSI)]
- Global Secondary Index (GSI) : 테이블과 완전히 다른 Partition Key와 Sort Key를 가질 수 있는 인덱스, 독립적인 양의 RCU 및 WCU를 사용 → 하지만, GSI 저장소 꽉차면 전체 트랜잭션이 실패돼 테이블에 영향이 가게 됨.
- Local Secondary Index (LSI) : 테이블과 동일한 Partition Key를 사용하고, Sort Key만 다른 보조 인덱스, 테이블과 용량 공유해 RCU와 WCU를 사용
[DynamoDB 낙관적 잠금]
- DynamoDB 동시성 모델 → Optimistic Locking 구현 : 조건부 쓰기 활용(업데이트/삭제(=쓰기)하기 전에 항목이 변경되지 않았는지 확인하는 전략, 각 항목에는 버전 번호로 작용하는 속성이 있음)
[DynamoDB DAX]
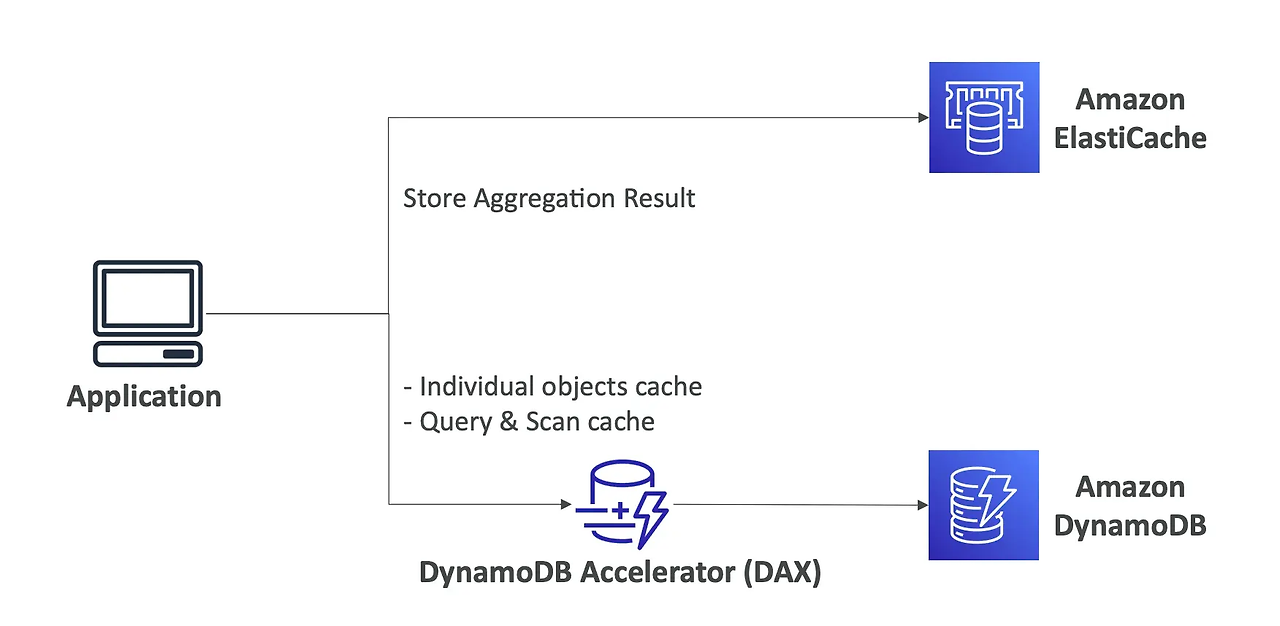
- DAX(DynamoDB Accelerator) : 최대 10배의 성능 향상을 제공하는 DynamoDB용 완전관리형 고가용성 인메모리 캐시 → 가장 자주 사용되는 데이터를 캐싱하여 DynamoDB 테이블의 핫 키에 대한 대량 읽기를 오프로드(DAX 같은 인메모리 캐시로 선처리하여, DynamoDB 자체의 읽기 처리량 소비(RCU)와 지연을 줄이는 것)
- ProvisionedThroughputExceededException 오류 발생 시 DAX 클러스터 활용
[DynamoDB Streams]
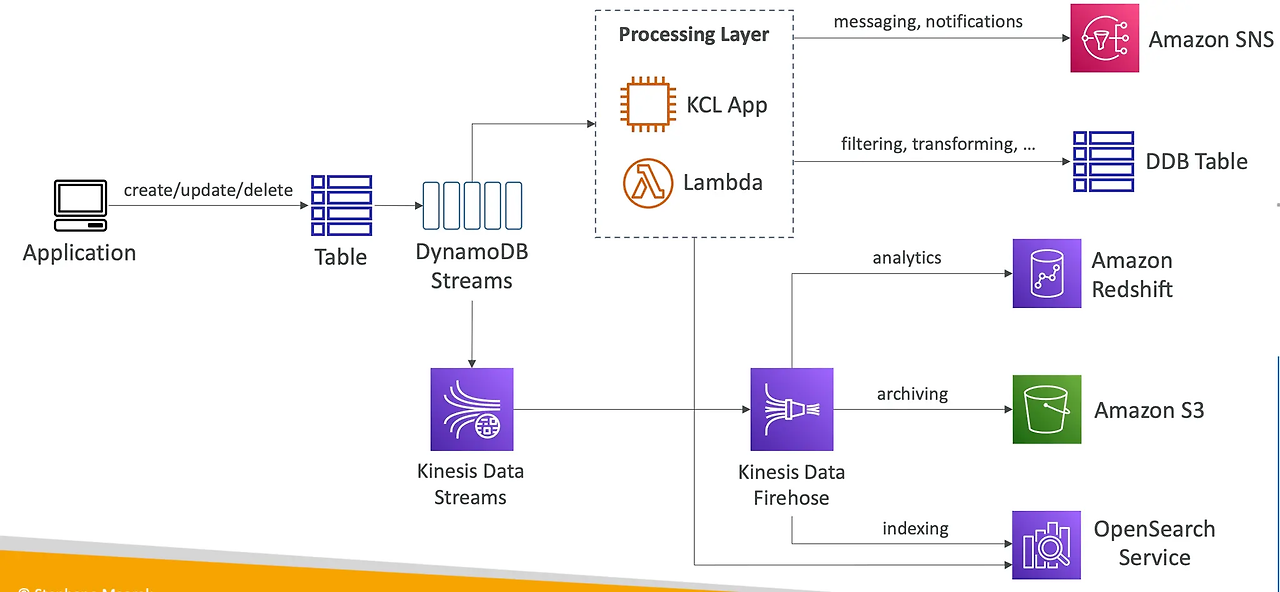
- DynamoDB Streams : DynamoDB 테이블에서 발생한 변경 사항(삽입, 수정, 삭제)을 순차적으로 캡처하여 실시간 이벤트 기반 처리를 가능하게 하는 변경 로그(Change Data Capture, CDC) 기능 (Lambda 연동 → 실시간으로 이벤트에 자동으로 응답하는 트리거를 생성 가능)
- Kinesis 데이터 스트림과 마찬가지로 샤드로 구성됨. (AWS에서 자동 조정)
[DynamoDB CLI]
- --projection-expression : 검색할 하나 이상의 속성
- --filter-expression : 반환되기 전에 항목을 필터링
- 일반 AWS CLI Pagenation 옵션 (예: DynamoDB, S3 등)
- --page-size: 하나의 API 호출 대신 AWS CLI가 전체 항목 목록을 더 큰 수의 API 호출로 검색하도록 지정합니다 (기본값: 1000 항목)
- --max-items: CLI에서 표시할 최대 항목 수 (NextToken 반환)
- --starting-token: 다음 항목 집합을 검색하기 위해 마지막 NextToken을 지정
[DynamoDB 작업]
- DB CleanUp → 삭제하고 재생성
- Copying DynamoDB Table → Data Pipleline에 EMR Cluster 사용
API Gateway
[API Gateway 이해하기]
- 스테이지(Stage) : API Gateway에서 배포된 버전을 식별하고, 환경별(개발, 테스트, 운영 등) 구분을 가능하게 하는 논리적 단위를 말함.
- 스테이징 캐싱(Staging Cache) : API Gateway 스테이지의 캐싱(Cache)은 API 응답 결과를 일정 시간 동안 메모리에 저장해두고, 동일한 요청이 들어오면 백엔드 호출 없이 저장된 응답을 반환하는 기능임. (기본값 300초)
- 주요 배포 전략 : Blue/Green(v1, v2 스테이지를 운영하여 점진적 전환), Canary(특정 비율의 트래픽만 새 스테이지로 라우팅 (Lambda 통합 시 지원))
Lambda + API GW : Serverless API 구현 (IntegrationLatency 지표 - 시간 초과 문제 분석)
Cognito + API GW : 사용자 인증(User Pool) + 인가(Identity Pool)
CORS 활성화 필수(기본값 : 비활성화)
클라이언트 측에서 API 캐시 무효화 : HTTP 헤더에 Cache-Control: max-age=0 전달
[API Gateway 주요 HTTP 오류 코드 정리]
- 400 (Bad Request) : 클라이언트 요청이 잘못된 경우 (예: JSON 포맷 오류, 누락된 매개변수 등)
- 401 (Unauthorized) : 인증이 실패했거나 토큰이 유효하지 않은 경우
- 403 (Forbidden) : 권한이 없는 사용자 접근 (IAM 또는 리소스 정책에서 차단된 경우)
- 404 (Not Found) : 요청한 리소스 또는 경로가 존재하지 않음
- 405 (Method Not Allowed) : 리소스는 존재하지만 해당 HTTP 메서드는 허용되지 않음
- 413 (Payload Too Large) : 요청 본문(payload)이 허용된 크기를 초과함
- 415 (Unsupported Media Type) : Content-Type이 지원되지 않는 형식
- 429 (Too Many Requests) : 과도한 요청으로 인해 할당된 쿼터 또는 속도 제한(rate limit)을 초과했을 때 발생, 쓰로틀링
- 500 (Internal Server Error) : 내부 서버 오류 (API Gateway 자체의 문제 또는 Lambda 통합 오류 등)
- 502 (Bad Gateway) : 백엔드(Lambda, HTTP 엔드포인트 등)에서 잘못된 응답을 반환함
- 504 (Gateway Timeout) : 백엔드에서 정해진 시간 내 응답이 없을 경우 발생
Code Series
[Code Series 이해하기]
- CodeCommit : 프라이빗 Git Repo (GitLab, Github)
- CodeBuild : 소스 코드를 컴파일하고 테스트를 실행하며 배포 준비가 된 소프트웨어 패키지를 생성하는 완전관리형 CI(지속적 통합) 서비스
- CodePipeline : CD (코드가 변경될 때마다 릴리스 프로세스의 빌드, 테스트 및 배포 단계를 자동화)
- CodeDeploy : CD (EC2, Fargate, Lambda 및 온프레미스 서버와 같은 다양한 컴퓨팅 서비스에 대한 소프트웨어 배포 자동화(배포 전략))
- CodeStart : 모든 프로젝트에 대한 CI/CD 원스톱 대시보드
- Commit(버전 관리) - Build(빌드 및 테스트) - Pipeline(빌드/배포 흐름 제어) - Deploy(최종 배포(배포 전략 등)) & CodeStart(대시보드)
[CodeCommit]
SNS + Lambda + CodeCommit : Git Repos에 자격증명파일 업로드 시 알림 및 차단 구성
CodeCommit 인증 방법(AWS CLI + HTTPS, SSH Key, IAM User + HTTPS)
계정 공유 → STS 교차 계정 액세스 활용
[CodeBuild]
buildspec.yml 파일은 항상 디렉터리 루트에 위치해야 함.
CodeBuild 컨테이너는 실행이 끝나면 바로 삭제됨(성공 또는 실패). → 실행 중이더라도 SSH로 연결 불가 VPC 내 컨테이너를 실행되므로 VPC의 프라이빗 리소스 액세스 가능(DB, 내부 LB)
S3 + CodeBuild : 종속성 캐싱 활성화(buildspec.yml) 빌드 시간 절감 가능
CodeBuild 내에서 명령 실행 가능 → static 웹 사이트 구축 및 static 웹 파일을 S3 버킷 복사 가능. CodePipeline으로 전달하면 정적 웹사이트 배포까지 구현할 수 있음.
[CodePipeline]
CloudWatch + CodePipeline : 파이프라인 실패 시 이메일 알림 구성
CloudTrail + CodePipeline : CodePipeline 관련 API 호출 추적 및 감시
[CodeDeploy]
LifeCycle : ApplicationStop → DownloadBundle → BeforeInstall → Install → AfterInstall → ApplicationStart → ValidateService
ValidateService : 애플리케이션이 배포된 후
온프레미스나 EC2 인스턴스에 CodeDeploy 에이전트 설치 필수
온프레미스나 EC2 인스턴스는 Immutable 배포 전략 사용 불가(컨테이너가 아니므로 불변할 수 없음)
SAM(Serverless Application Model)
[SAM 이해하기]
- SAM : 서버리스 애플리케이션을 정의하고 배포하기 위한 오픈소스 프레임워크로, AWS CloudFormation을 확장하여 Lambda, API Gateway, DynamoDB, Step Functions 등 서버리스 리소스를 간결한 문법으로 정의함.
- AWS::Serverless::Function → Lambda 함수
- AWS::Serverless::Api → API Gateway
- AWS::Serverless::Table(or SimpleTable) → DynamoDB
- 이외에도 S3 정책 설정 등 가능
- SAM → AWS 업로드 명령 : sam pacakge && sam deploy or aws cloudformation package && aws cloudformation deploy
- SAM CLI + AWS Tool Kit : Lambda 함수를 로컬에서 디버깅 가능(변수 검사, 코드 한 줄씩 실행 등)
- SAR : SAM Package를 다른 AWS 계정과 공유할 수 있음
[Serverless 기타 서비스]
SES : 대량 이메일 / ACM : 인증서 중앙 관리 / Macie : 민감 데이터 보호 / OpenSearch : 검색 엔진
Cognito, AWS AD
[Cognito 이해하기]
- User Pool : 인증 (Lambda를 사용해 Authentication Hook 작성 가능) → 인증 성공 시 JWT 반환 API GW, Lambda와 통합해 요청 인증 가능
- Identity Pool : 인가
- Hosted UI : User Pool에서 제공하는 AWS가 호스팅하는 웹 기반 로그인 페이지로, OAuth 2.0 및 OpenID Connect(OIDC) 기반의 인증 플로우를 쉽게 구현 지원 (JS 커스터마이징 불가)
[AWS AD 이해하기]
- AWS Managed Microsoft AD : 완전관리형으로 제공하는 Microsoft Active Directory 서비스 사용자는 DC를 직접 관리하지 않고도 AD 사용자, 그룹, GPO, LDAP, Kerberos 기반 인증을 사용 가능.
Step Functions, AppSync
AWS Step Functions : AWS 서비스를 오케스트레이션하고, 비즈니스 프로세스를 자동화하고, 서버리스 애플리케이션을 구축하는 데 사용되는 로우 코드 시각적 워크플로 서비스임.
- 여러 Lambda 함수를 병렬로 실행한 뒤 하나의 최종 결과로 확인 가능.
- Lambda 함수 연동 시 실행에 필요한 IAM 권한을 Step Function Workflow에 부여해야 함.
AWS AppSync : DynamoDB, Lambda 등과 같은 데이터 소스 연결 작업을 처리하여 GraphQL API를 쉽게 개발할 수 있도록 하는 완전 관리형 서비스임.
- WebSocket 지원.
Security
[AWS KMS] : 암호화 키를 생성, 저장, 관리, 회전 및 감사할 수 있는 완전관리형 키 관리 서비스
- KMS 키 (CMK, Customer Master Key) : KMS에서 생성되는 암호화의 중심 키
- 대칭, 비대칭 지원
- 고객이 직접 생성/관리하거나, AWS 서비스가 자동 생성 가능
- 데이터 키 (Data Key) : 실제 데이터 암호화에 사용되는 일회성 키
- KMS 키(CMK)로 암호화되며, 데이터와 함께 저장됨
- 복호화 시 KMS에 Decrypt API 요청 필요
- Envelope Encryption 지원 (큰 데이터(4KB 초과) 암호화 처리 시 적합, GenerateDataKey API 호출)
- 키 정책 (Key Policy) : KMS 키에 대한 정책 기반 접근 제어
- IAM 정책과 함께 작동하며, 둘 다 허용(AND 조건) 되어야 사용 가능
- 특정 IAM 사용자, 역할에 권한 부여 가능
- Alias (별칭) : 키 ARN 대신 참조할 수 있도록 제공, 예시) alias/my-encryption-key
- 키 자동 회전 (1년 주기)
- CloudTrail을 통한 모든 키 사용 이력 로깅
- FIPS 140-2 인증 하드웨어 보안 모듈(HSM) 기반 키 저장
In-transit encryption : SSL + HTTPS Endpoint
S3 버킷에 저장된 객체에 SSL 요청을 적용할 수 있는 IAM 정책 조건 : aws:SecureTransport
Server-Side Encryption
- 서버 측에서 데이터를 암/복호화 (대칭키, 비대칭키 모두 지원)
- EBS, S3, RDS에 대한 암호화 : AWS Managed Service 키 사용 가능(KMS 자체 키 생성 필수 아님.) *주의 : 암호화 이후 사용된 CMK도 함께 공유 필수.
- S3 SSE-KSM 암호화 후 인스턴스에서 버킷에 접근해 다운로드 시 S3:GetObject 뿐만 아니라 KMS: Decrypt 권한도 함께 필요.
Client-Side Encryption
- 서버 측에서 암/복호화를 하지 않으므로 서버에서 사용 중인 암호화 체계 몰라도 됨
SSM Parameter Store : 비밀을 저장하는 데 사용할 수 있으며 버전 추적 기능이 내장돼 있음. 파라미터 값을 편집할 때마다 SSM Parameter Store는 파라미터의 새 버전을 생성하고 이전 버전을 유지함.
AWS Secrets Manager : DB 비밀번호 등 민감 정보 저장
'Certificate > AWS DVA-C02' 카테고리의 다른 글
| [AWS] AWS DVA-C02 취득 후기 (1) | 2025.05.10 |
|---|---|
| [AWS DVA-C02] 덤프 오답노트 (0) | 2025.05.02 |

